 Oddbean new post about login | logout
Oddbean new post about login | logout We're building the new Goodreads @MyLibrarian! The app has a book tracking tool like you describe. Sign up for the beta waiting list at BooksLibrariansLove.com
do you need to use an email?
To sign up for the waiting list
kk
Ah, that's interesting. 🤔
Are you going to be using 30041 events as cards, for a book catalogue?
@verbiricha, @purple.co, @DanConwayDev and I were actually fiddling with a way to rate git repos, that could also be used for articles, books, videos, etc. You can see the proposal here: nostr:nevent1qqs9y5n56zdfzfnzc7xn3j8q6wjsyduyqgcdrd99vzc8lrh3lj9ekqspp4mhxue69uhkummn9ekx7mqzypl62m6ad932k83u6sjwwkxrqq4cve0hkrvdem5la83g34m4rtqegr9rjdm
FYI. Let's figure out a universal way to do ratings, so that we don't block future use cases. We could use and display them differently, in our apps (@nielliesmons has been trying that stuff out), but write the events the same way. Also interesting for rating pics @highperfocused ⚡ nostr:nevent1qvzqqqqqqypzphtxf40yq9jr82xdd8cqtts5szqyx5tcndvaukhsvfmduetr85ceqydhwumn8ghj7argv4nx7un9wd6zumn0wd68yvfwvdhk6tcpr3mhxue69uhhg6r9vd5hgctyv4kzumn0wd68yvfwvdhk6tcqypmr5zag2puukcqvy3r4zfkj8ljn765mhnu49rd3ew9nk7e3fytf6mgsn4g
Would be good to get more input in GitWorkshop.de for that proposal. https://gitworkshop.dev/r/naddr1qq9kw6t5wahhy6mndphhqqgdwaehxw309ahx7uewd3hkcq3q5qydau2hjma6ngxkl2cyar74wzyjshvl65za5k5rl69264ar2exsxpqqqpmejfryfcu/proposals/note12ff8f5y6jynx93ud8rywp5a9qgmcgq3s6x622c9s0780rlytnvpqpnrxnh/
@jb55 and @Vitor Pamplona and @hzrd149 might be interested in that, too. For Wiki pages and articles.
And @PABLOF7z @Michael J and @fiatjaf
The proposal is actually for "favoriting" a repo, but I'm wondering if ratings shouldn't also be a list, or should they be labels, or... What do you think @liminal ?
Also, and maybe this is heretical, but could a type of rating be something calculated by WoT starring, and number of references or etc.? Does that increase or decrease information? That would be an importance/significance-rating, in other words, and cut out the typical data noise of human rating systems.
nostr:nprofile1qqs8y6s7ycwvv36xwn5zsh3e2xemkyumaxnh85dv7jwus6xmscdpcygpz4mhxue69uhhyetvv9ujuerpd46hxtnfduhsz8thwden5te0dehhxarj9ekh2arfdeuhwctvd3jhgtnrdakj7qghwaehxw309aex2mrp0yhxummnw3ezucnpdejz7qxvpy4 nostr:nprofile1qqs0dqlgwq6l0t20gnstnr8mm9fhu9j9t2fv6wxwl3xtx8dh24l4auspzamhxue69uhhyetvv9ujumn0wd68ytnzv9hxgtcz9359y nostr:nprofile1qqs2js6wu9j76qdjs6lvlsnhrmchqhf4xlg9rvu89zyf3nqq6hygt0spzamhxue69uhhyetvv9ujuvrcvd5xzapwvdhk6tcprpmhxue69uhhyetvv9ujuumfv9khxarj9e3k7mf0qythwumn8ghj7un9d3shjtnwdaehgu3wvfskuep0pk63va nostr:nprofile1qqsd5x8fscqypualfyu8dlqkkx539tj6dah634g4ns779wpr8gxes5gpz9mhxue69uhkummnw3ezuamfdejj7qg4waehxw309aex2mrp0yhxgctdw4eju6t09uq3uamnwvaz7tmwdaehgu3dwp6kytnhv4kxcmmjv3jhytnwv46z7r379p8 and a few others were discussing the virtues and drawbacks of WoT rating systems in Riga.
Ah, cool. Yeah, it seems like WoT and our ability to see all sorts of events raises the ability to simply calculate ratings. Like, if an event describing a book has 15 Labels and 2 embeddings and 492 comments and 32 quotes and 5917 stars, and your friends are all over it... then it should probably have a high rating. And that rating should be higher for you, than for someone whose friends don't care about it. Relative, calculated ratings.
The 5-star manual entry seems very "We just figured out 1-click shopping carts".
@franzap is a 1-5 star rating system maxi
Well, it's easy to implement and simple to understand. You could add those into the subjective, overall score. Where are you writing the ⭐⭐⭐⭐⭐ @franzap In a label? I'm assuming that zapstore will let us rate repos.
If I rate a repo on GitWorkshop, can that get included in the Zapstore score? Don't want to have to rate the same sort of thing in 15 different apps.
If there were a two way relationship between the 'application profile' in the app store NIP and the 'repository announcement' in nip34, then clients could associate those ratings with both things. currently it is one way (nip34 announcement is referenced by the application profile event).
If it were bidirectional, then I could click on a link in GitWorkshop and it would open in Zapstore and I could download the release there, right? And do we bookmark repos and rate releases? Are those two different levels of information?
Like, the ngit binaries are on the GitWorkshop web page, but they could theoretically be in the Zapstore, I think. That would mean that you could issue the binaries as an event and just display the newest event in GitWorkshop. Or does that make no sense? 😂 I haven't used Zapstore, yet.
As of yesterday they are now in zapstore. I plan to display all releases related to a git repository in gitworkshop.dev
Oh, cool! I need to check out Zapstore, I think.
Yeah, it is pretty cool
Wow, that's an exciting integration.
I know right. its the magic of nostr. it is why we keep showing up.
a repo might have an iOS, Android and Web application profile, and the opinions of those profiles should be somewhat separate because the UX might vary significantly. I think opinions are more likely to be made against the application profile than specific releases. I'm unsure of the best way to gather opinion heuristics in this area and how to display them to the user.
Ah, right, so it's one repo to n applications. 🤔
yes
You don't want to rare anywhere. Zaps, replies and shares are enough. They are universal things you can do on any content type. They are high signal and users do them anyway fir other reasons. LLM's and other types of computation can pick it up from there and show you whatever kind of synopsis stuffed to the aircofuck content type / user preference. If you prefer your synopsis to have some kind of ⭐⭐⭐⭐⭐ rating, go for it. But I'm not entering those.
*rate
I like the ⭐ bookmark, idea, and combining that with the other data to create a rating. Bookmarking a repo or a movie or book seems very high-signal.
Yes, public bookmarking is extremely high signal. It's in the "Share" category for me because it can take many shapes: - share to your own public bookmarks - share/host in a community - share in Stories - ...
Zaps and replies are high signal, true, but you need relative measuring here which they don't provide. You might have an excellent app that got 2x 21 sats, vs a mediocre app that got 10x 5 sats but simply because it was discovered a bit earlier. The computation will give 2 stars to the former and 5 to the latter? Plus, you introduce another thing to trust (the computation). Ratings are signed by users and are incredibly low friction - in the context of wanting to rate something, write, zap, etc
Don't see a rating event described, yet. Don't know if the newest version is published. https://github.com/zapstore/zapstore/wiki/Sample-app-events
Not writing ratings yet, we were just talking about it. @nielliesmons is totally against them. I'm not, I think it's a short way of expressing an otherwise written opinion (plus its low friction). I would use NIP-32 (on a NIP-94 file metadata) for rating a release. I don't think it's equivalent to rating a whole repository. First because it's fine grained (release) and because it's the actual product the user is using. The repo is way more general and upstream.
Ratings statistical noise, to be honest, and not as signal-loaded as our other data. Other places need ratings because they don't have as much other data.
Sure, I will only be persuaded when I actually see a computation yielding decent ratings from zaps and comments. Sorry if I'm very skeptical.
Challenge accepted, sir. 😁
I can already tell you that the rating for this thread is off the charts 😅
Don't you think Amazon has plenty of review data? They can verify purchases. Why do they keep using stars?
Damn near impossible to roll back a primary feature that you popularized. 😂 Everyone would totally freak out, especially as they would keep generating ratings and sorting and etc. and everyone would be creeped out. Lots of apps get stuck with emotional technical debt, like that.
Besides, they do so much computational magic on the stars that it's basically closer to what we're suggesting. They only count the stars directly, if they think the rating makes sense and is useful. https://www.wired.com/story/amazon-stars-ratings-calculated/
I don't care about what Amazon does with stars. I just want a 5 star rating for books. You guys can do whatever you want with the system for other stuff... But every book app I've used has a 5 star rating system that I tend to prefer for reasons stated below.
“emotional technical debt” Nothing is purely technical and nothing is purely emotional. https://media.tenor.com/B-TP3rs3l7IAAAAC/memory-cant-remember.gif
People get emotionally attached to UX. Like how there are often fields in online forms that the company doesn't need, but they have to put them there because people get upset if they aren't there. So, they just collect it and store it, but don't use it.
Yup, exactly why 80% percent of the time copying Big Tech UI/UX isn't a graat idea. We have a chance to do something new here, where the user has to perform and understand way less actions. Big tech can only dream of letting their users reply on, zap and share literally everything, so they invented a bunch of proxy features. They had to make these features look and feel like lottery machines because otherwise no one would even use them. We don't have that problem. If you do, you're designing it wrong. Replying, sharing and zapping are examples of some if the most natural UX you can find.
#bigtechcope
Have you thought about badges?
but also I have friends who I have little overlap in movie or restaurant preferences. The fact that they liked something actually signals to me that I wouldn't like it.
Yeah, I actually think ratings are most interesting to show significance or familiarity. That's why I don't know if more than one ⭐ adds much. Comments are more interesting. Comment-significance would also be useful. Some comments are just retarded.
In Riga we were discussing having a 1) a generalized DVM that finds events that indicate an opinion on the thing (product, app, etc) and filters out the SPAM; that feeds into 2) DVM specific to a usecase that takes that opinion data and summarise it in a whay that is useful to a client. eg so they can prioritise its display in the interface or express the opinion through words, emojis or, god forbid, a 1-5 star rating.
My worry is that it's going to be a hot data mess to wade through, if we end up with ratings in different types of events. I mean, you can always crunch the numbers, but it seems like a waste of processing, if we just have to crunch because we didn't bother to write down a suggestion for where/how to document it. They already finished the librarian app, with ratings in it, and that data is going to be swirling around, already. But, whatever, Nostr will melt the glaciers. 😏
Like, we could end up with Bookmark ⭐ , Label ⭐, Kind 01 ⭐, Embedding ⭐, Emoji ⭐ (overloading the other emojis, see it coming), etc.
but numeric rating systems are only so useful. evaluating other heuristics can lead to more accurate summary of the opinion of your community.
Yeah, that's what we're saying. Rather than promote the idea of 5⭐, we can just do ⭐bookmark, like you were planning, and combine it with all of the other data we have.
My question is: where to put the 🌟? 😂 Devs will be putting the 🌟 all over the place.
😂 step 1. log into my app, step 2. automatically sends 5 star review with glowing comments without you realising.
as we live in a bazaar, you can control how other clients might 'abuse' a carefully thought rating system. for example someone may have designed a 1-5 rating system for an event kind and use it extensively in their app. Another client presents the user with the option to star the same event and sends in a 5 star rating.
Did you see that I accidently gave my own relay only a 3-🌟 rating? 😂
haha. who ever uses 3 stars? its 1, 4 or 5.
I do. Often. I prefer a 5 star system based on this: 1 star: just bad 2 star: meh 3 star: ok 4 star: good 5 star: excellent Given my original use case for this, books, a 5 star system is pretty much mandatory, IMO. 1 is not enough as it just signals that it's of interest, but not WHY. Three is better as you can indicate positivity, neutrality, or negativity, but nothing more. Ten stars is dumb and I have no use for it. Therefore, I prefer and will always advocate for a 5 star rating system for books. Other types of media are fine with a 2-3 indicator system. (Old school thumbs up/down are useful, and effectively a 3 indicator system given that you would have to really like it dislike something to bother with giving a thing a thumbs up or down.)
5 star rating systems are used by data driven tech companies which have huge resources to study their effectiveness, such as Amazon. The fact that they haven't moved away from it is signal that its useful.
We use a 5 star rating system in the LibrarianBrain.com data set
Which event kind do you store the rating in? Like, which NIP are you using for documenting the rating?
I'm going to start a new thread for Building the MyLibrarian Community in Public #buildinpublic and share information there.
Communities in nostr: ew. (currently, hopefully not for much longer)
Have you checked out Ditto
No. I am annoyingly churlish about wanting to only use two clients. I DETEST trying to do stuff on what should be a fully interoperable protocol on multiple clients eating away at my battery in the background. It's exceptionally inefficient and the reason why I also detest using skads of the raspis to do stuff when one, more efficient and much more powerful VM server can handle all of those things. I love nostr, in theory. I hate nostr as currently implemented. Yes, I realize this is unproductive and childishly stubborn. 🤷♂️
We have built this in a database we call the Librarian Brain, currently in Postgres, on which our apps run. Our social community is on Nostr. So events for social with NIP-57 for sure. Still starting to build ✨⚡️
I don't know that they _can_ move away from it, as people really enjoy clicking on the stars and actively "voting". It's cathartic, for the user. So, the usefulness is probably more about retaining user loyalty than merely gathering high-signal information. A lot of the ratings are just garbage, like trolling mobs, bots, the competition, or idiots complaining about the package being dropped by the postman, or whatnot. They quietly drop or underweight all the garbage, and overweight their power users and real customers, to keep the overall rating relevant.
100%
I couldn't care less about that. I just want to use a 5 star system on a book app. Big tech gets everything "wrong." let's not bother with that fiat mindset.
I think it's funny that you think the bad thing is not the 5⭐ system, it's Amazon's attempt to protect small business owners from malicious and idiotic raters. Anything strictly numeric, with little or no cost, will be gamed.
completely agree
*sighs* There's a lot to unpack in that one statement, as usual. 1. IDGAF about businesses, in general. The app/system I want is not a business. I want to be able to rate and share book recommendations with fellow nostriches. 2. I can parse BS reviews from others. I know that's not a universal quality. I am ignorant of how things can be "gamed" since I don't think about things like that and am more honest than most. 3. I suppose my view of this is rather myopic since I don't expect this to be used by very many people for a very significant period of time. I'm overall very skeptical of nostr super-adoption, so... I can deal with a preferably simpler system at the beginning that is coded to be flexible enough to add in enough Pow to prevent gaming later. Start simple, but start!
1. Authors are creators and therefore producers. That's a business, even if they aren't expecting monetary profit. It's negligent to put something so destructive into place, without even thinking through the consequences. 2. Has nothing to do with honesty and everything to do with decades of experience in data analytics and UX. It would take someone 1 hour to create a script that just spits out fake ratings from random npubs. 3. Once you get everyone used to the 5 ⭐ system, you can't roll it back in your app. 4. The ratings are only useful, if there are a lot of ratings. The thinner the volume of the ratings, the easier they are to game. That's why a lot of websites actually hide ratings until they have at least n number of high-quality ratings on the item.
I will have to bow to your decades of experience in this field. I couldn't care less about most of what you mention, too be honest. As an aspiring author, and one with strong opinions and also the tendency to put very unpopular ideas into my writing, I expect that my books won't be popular with certain (woke) subsets of readers, and could expect bad reviews from many people. I just don't care. I suppose it is still wise to take prudent steps to mitigate scripting attacks. One stupidly easy way is to have a simple "freemium" model where you can use the entire app for free, but if you wish to push your reviews to others/in public, you would need to pay a significant but not egregious amount of sats in order "go public." This would also help fund development while simultaneously preventing tons of new bots from ransacking the system like the Goths in Rome. If someone wanted to spend that much to leave bad reviews, cool. It's funding the app. I would still consider that a win for the overall system. Thoughts?
I thought of the same thing, or even something simpler, like zap-to-rate, so that you have to pay the author, in order to post a rating. Then only someone highly-motivated would bother. Freemium would have the advantage that malicious raters could get their contract cut and their ratings removed, so that would pressure them to be behave and stay constructive. But I don't know. I understand that some users like giving the ratings, but others find the pressure to rate really irritating and refuse to do so (which reduces the signal of each rating, as it's a self-selected subgroup giving the ratings), and I question whether other users benefit from the ratings on-net. They seem to mostly be a way to press the advantage of big players (number of ratings leads to higher average ratings, in addition to their natural advantage of simply having lots of reviews and customers/users/bookmarkers), and reduce the visibility of newcomers, as everyone sorts the results by stars. I'm not saying that I'm 💯 against it, but I'd be very cautious in implementing it and I'd be aware that the implementation burns all data bridges. You put it in there, you have to leave it in there forever. No take-backs.
I can't stand Micro-transactions. One and done for me, thank you very much. You did bring up an interesting twist, though... If somehow an author of a book is verified (my goodness, that hurts me brain thinking about), them getting a cut of review sats makes sense. So now I'm conflicted. 😅 Thank you.
Well, I mean... would you mind people giving you bad ratings, if they had to pay you for the privilege of doing it? Authors could even determine their own price, right? Half a Bitcoin for a 1⭐ and you can put whatever crap in the comment and we're good. 😅 Two comments and I retire. https://c.tenor.com/_rafdjAM5zIAAAAC/tenor.gif
That's, again, a lot deeper than I was thinking. But, that could also be a bad thing. I don't think that it should be possible to set a minimum price per star rating. It would be better to have one price to rate at any star. If that's the system to go with.
I get that the incentives are skewed. but they are pretty effective at attracting and retaining large number of users. to achieve this they do heavily surveillance on user activity, many iterations of a+b testing tweaks to their UI to create UX. If we can learn lessons from them, so long as we critically evaluate knowing they are prioritise attention and retention above satisfaction and well being.
All of that is only relevant if you're building a business to make profit. This is not that. Stop bringing that stuff into the nostr protocol. It will poison the well.
What do you mean by that stuff? I'm a big privacy advocate and hate the heavily surveillance of user activity which is used to dominate and control us. but we can use their learning to improve user retention and provide better experiences.
IDGAF about "user retention." A better experience is just a very simple, clean, easy to understand UX that just works. I know how that should function at the user. The bank end stuff is what I don't know Jack about. A clean, simple, straightforward user interface will do the most to "keep users coming back." You only need to stick to: -automagic book lookup by title, author, barcode, or ISBN -automagic cover lookup for said titles, as an option. I know some don't care for the clutter of book covers in a clean list view. -three lists: reading, to read, read -ratings upon completion -it's not hard, I guess, to also allow written reviews but I don't think that's necessary for a first iteration -nostr connectability to the whole ecosystem, but specifically to be able to share links to books, reviews of books, and curate a separate list of connected npubs to "follow" and possibly another list of npubs to "push notifications to" when I book is finished/reviewed/added to the list "to read" list -further iterations might include a user curated and "recommended list" that others can easily add to their "to read" list, in part or total But at this point I really should be doing my fiat mining job instead of building out all the app features. My point is that I really don't care about concerns of retention. That's not at all a metric that matters to me, as a user.
As a creator of tools which I hope will bring value to those who use them, user retention is a useful measure of whether user received value enough to return.
How would you figure that out without being intrusive? (That's mostly a rhetorical question to get me to think about how I would do it.) I'd rather use sats as an indicator. If people will pay for it, it's valuable. See my reply to one of Stella's notes.
Simplistically, if someone starts posting git events but then stops, then they havn't been retained.
1-4 is bad bad bad. 4-5 is good. It's actually a binary system because almost everyone who doesn't hate it, gives it a 4 or 5. Items with lots of ratings usually have 4+ because of the way things average out, whereas newcomers and small businesses tend to have terrible ratings because one bad rating can skew the whole scale. You can terrorize or bankrupt small companies or creators with a few bad :star ratings. So, if they get some bad ratings, they will often ask friends, employees, etc. to login and give it some more good ones. 😅
I read, somewhere, that a perfect rating is actually 4.7 because 5 sounds too good to be true, so some companies write a couple fake bad reviews, to get below a 5.0. 😅
That makes sense to me.
Another thing to consider is that people can rate the raters. The information is bidirectional. (Like, on AirBnB, people who have left others bad ratings are more likely to be turned down by the next place. Or an author that leaves bad reviews on other people's books opens himself up to having them leave bad reviews on his books. Someone who rates products as sub-4 might find that other companies send him out-of-stock notices, instead of sale confirmations.) And this bidirectionality would be even more leveraged, on Nostr, as it would hurt your overall WoT score and follow you around. That means there's a natural disincentive to give bad ratings, as they can boomerang, so you either need to be such a top expert, that you can afford to be critical (and hardly anyone is) or you only give good ratings or no ratings.
I'm pretty immune to issues like that since I have very little concern for "my reputation" at large, only that my friends know that I am trustworthy. Outside of that, IDGAF. If something is bad, it's bad. I can separate a badly written book from one that I disagree with. I have very little issue going against those types of incentives. I know that I'm rare in that way, but... It annoys me that those are even consideration that people worry about. Keep things simple, iteratively improve. Deliver a working product then improve.
You’re 🎯 about the hot data mess. No way around that, ever. We may as well come to grips. Which means that as a consumer of the hot mess, you’ll have to interpret data that comes packaged in multiple formats. Each external format needs to be interpreted into a *single common format of your choosing* so that you can synthesize them all together in a way that is of maximum utility to you.
Yes, but if the majority are interoperable, that raises the pressure on others to use the same event type for the same data type, unless they can prove that they have some novel use case that requires a different tactic. Which is possible. Like, if Zapstore is using labels for ratings, I'll just use labels. I don't need to invent a new "rating kind", just to be a jerk about it. My incentive is to just go along, to retain interoperability and not preclude future use cases. That's part of the magic of Nostr.
It’s true that if everyone else is using some specific format or nip for ratings, then it’s in my interest as a dev to adopt the same system. This is how we avoid a Tower of Babel type situation. But it will never boil all the way down to a single global format that we are all forced to use. There will always be multiple formats. If we know how to synthesize multiple formats from multiple data sources together to answer a single question, like what’s does my WoT put at the top of my rec list, that’s a good thing. Problem: how does my WoT rank widgets from top to bottom? Data source 1: vendor follows, mutes, zaps Data source 2: 5 star ratings of the widget from store A Data source 3: emoji reactions on adverts of that product on a nostr classified ads client And I’m sure we can think of MANY more data sources than those 3.
Edit: Data source 2: 5 star ratings of the widget from stores A, B, C, and D, plus 0-100 point ratings from store E written by some pain in the ass nonconformist weirdo dev who uses a different format for reasons you may or may not agree with or even understand
Answer: the grapevine method synthesizes all these data sources into a single score. If you want to buy a widget and your fav nostr store has listings of 1000 widgets from 1000 vendors, why not use ALL of the above data sources to rank those 1000 products from top to bottom?
That's a complicated set of math to do.
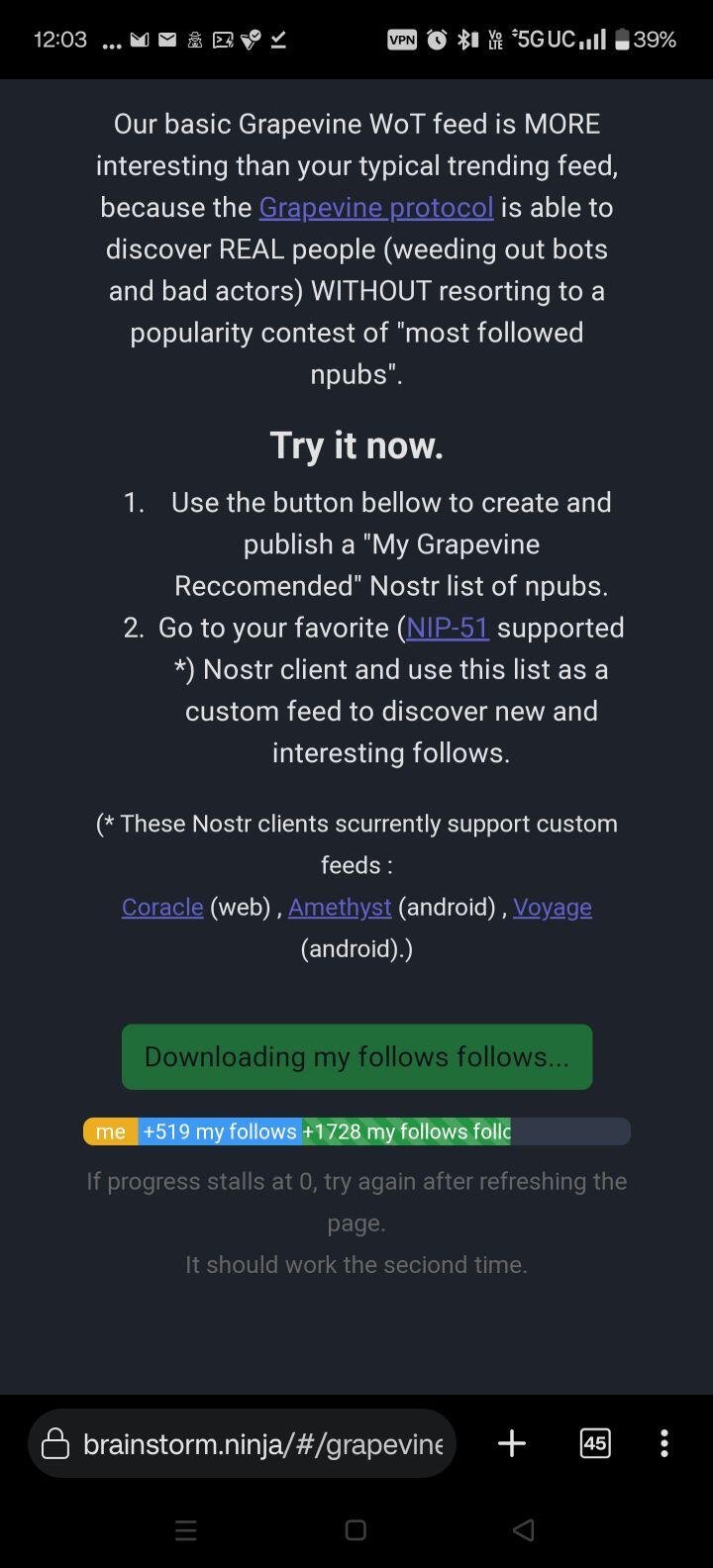
Yes but quite doable. Too much to do on the fly on the front end, but the heavy lifting can be done ahead of time on the back end. I built a front end demo using only two data inputs (follows and mutes) which is how I realized it’s too much for the front end. @ManiMe streamlined the download process into a single click and you can try it out here: http://grapevine.my It will output the top 1000 recommended pubkeys minus the ones you already follow as a NIP-51 list which you can upload to a few clients (Coracle, Amethyst, nostrudel maybe?) and browse the feed when you get tired of you follows feed. Great way to discover new high quality follows. @cloud fodder and @ManiMe and I are working on replicating the above but calculating scores on the back end using a relay that already has follows and mutes data, so no need to dump all of that onto the browser, much better UX.
So I did that and have no clue how to view that list on amethyst. Not your problem, just, trying to see the output.
Can any #Amethyst users help a beaver out? How to import a NIP-51 list and browse a feed and whatever else you can do with it? #askNostr
Ah. I see. It's just a filter that you apply, basically. I can't see see the list itself, it is just applied as a filter. That's... Not exactly useful. I don't see anyone new on that feed at all.
No one new? It should omit the pubkeys you’re already following when it builds the list. Did it not do that?
Yup. It's literally a feed of me. Kinda weird, TBH
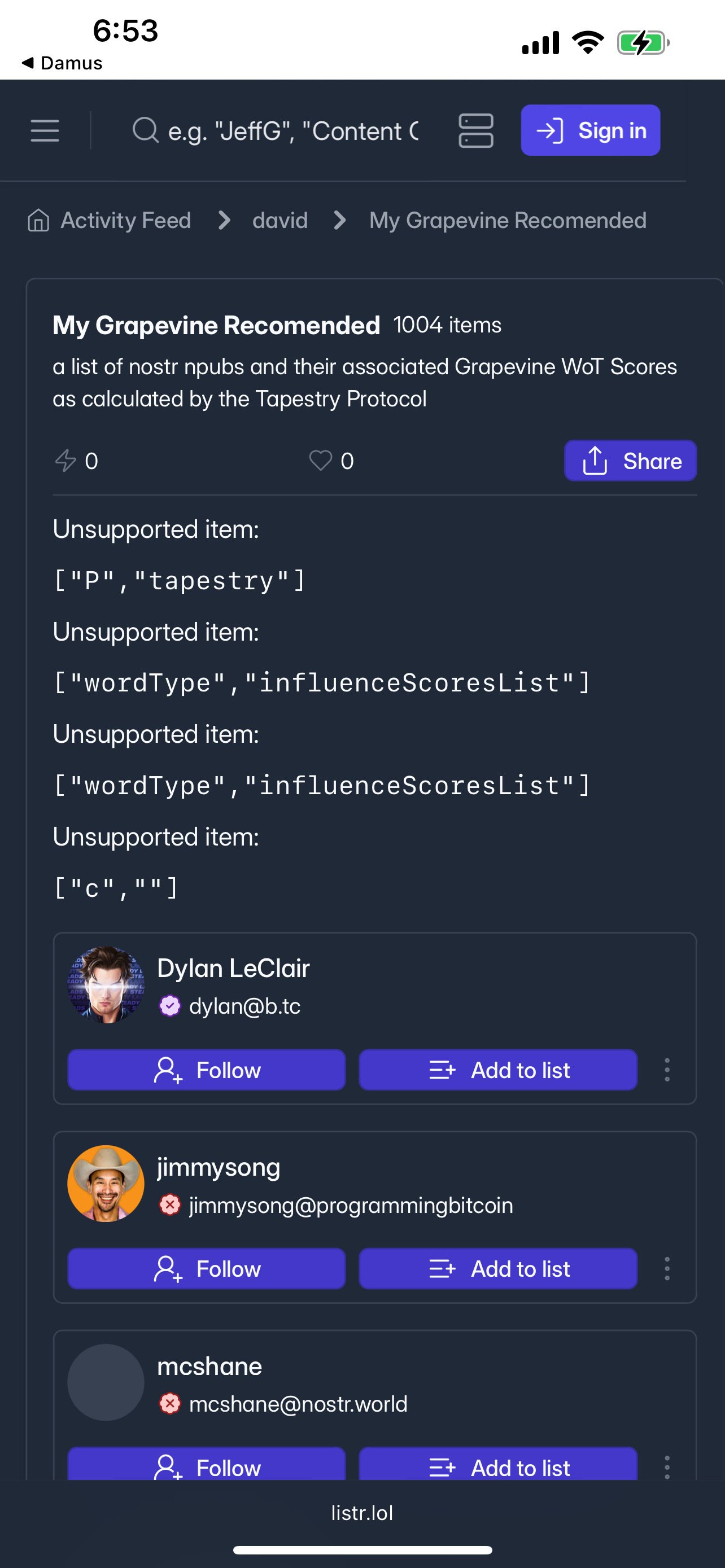
I see your list — yeah, didn’t populate it at all except for your pubkey. Check out my Grapevine list on listr to see what it is supposed to look like. When you built the list were you signed in using an extension? Smartphone?
I can't figure out how to see lists via a different npub. Yes. An extension (nos2x, IIRC) on an android phone with kiwibrowser.
We haven’t tested list generation on android — maybe that’s why? On listr you can browse lists of other npubs. Search by username at the bar on the top. Or go to listr main page Activity Feed and right now I see one or two My Grapevine Recommended lists recently updated — the first two I click on seem to have worked (mostly) correctly (except only 878 items, should be 1000? 🤔)
I get an error 504 when I click on your grapevine list. I dunno what else to try. 😅
On listr? See if this works: https://listr.lol/npub1u5njm6g5h5cpw4wy8xugu62e5s7f6fnysv0sj0z3a8rengt2zqhsxrldq3/30000/naddr1qqfkjmnxd36k2mnrv4fkxmmjv4e5c6tnwsq3vamnwvaz7tmjv4kxz7fwdehhxarj9e3xzmnyqgsw2feday2t6vqh2hzrnwywd9v6g0yayejgx8cf83g7n3ue594pqtcrqsqqqafse7w7jf
That mostly works. I can see the list, just not nyms or avatars, so I don't know who anyone on that list actually is.
Here’s what I see (not logged in) https://i.nostr.build/GuHLzgOKpohPWAGh.jpg
Trying the grapevine thing again, it stalls. https://image.nostr.build/448c86f69873eca7e2b8f69d0b9ad9b9695e3740f155d8e84dc12014d045967e.jpg
It's working now. Using the hammer method worked. 😅
I find listr useful to view the list itself. It’s easy to scroll down and check who you’re following and who you’re not. At first we just exported the top 1000 and you’d get a mix of current follows and suggested follows, but then we figured we’d omit current follows so you’d get a fresh feed from high quality pubkeys. Soon you’ll be able to generate multiple lists. With / without current follows; Grapevine page 1, page 2, etc
Your “My Grapevine Reccomended Follows” list was published to Nostr from grapevine.my. You can confirm this using listr. I haven’t personally tested on android (yet) but I believe you can make custom feeds in Amethyst, using Nostr user lists?
Interesting. If I could see the output. How do I see lists on amethyst? #asknostr nostr:nevent1qqs95jmlcjd4lhdq3qqa78g0wjwa4gkaehaf6zxaksux96rvwgflj7cpz4mhxue69uhhyetvv9ujuerpd46hxtnfduhsyg89yuk7j99axqt4t3pehz8xjkdy8jwjveyrruync50fc7v6z6ss9upsgqqqqqqs34lypr
Yes it is complicated. But there are a “finite” set of these data types (Nostr event kinds that interact with other events in ways that may be interesting for WoT) to calculate. There doesn’t need to be a standard of “which data types” should be used “in which manner” by clients. Some de facto standards may arise, while other algo inputs will only increase in complexity. Standards are not as important as adaptability. For the foreseeable future, developers of WoT recommendation engines will have to keep their ears to the ground to adapt their algo inputs accordingly. But this complication does not need to be developed all at once or overnight. Mind you, this is a new perspective for me. It’s much easier to just say “let’s make a standard”, to make development easier. But life IRL does not work this way. Life adapts. So we must learn to adapt as Nostr grows. Today we do this. Tomorrow we do a bit more. Baby steps.
The grapevine method is the best response I can think of to the XKCD on standards that we all know and love: https://i.nostr.build/fUEDsBnkQhR9IVc5.jpg
I think there is value here, when it comes to products or restaurants. For example, u could do a weighted average, that at a glance shows u relevant information. Instead of having each review/rating have the same weight, one could give more importance to your follows. e.g. your follows have weight 1. npubs 2 hops away have weight 1/2, then 1/4 and so on. The idea is that people closer to u will have an opinion that is probably more relevant that people far away from u
You could also value to the rating of npubs that like the same things you like more.
yes, but that can be tricky against targeted attacks. Like, I wanna make u buy this thing, so I'll spin up millions of nibs that have precisely your interests, so I'll skew your ratings. Unlikely, but possible
it wouldn't take much computing power to produce those events, but relays might reject them as SPAM if they have old timestamps. Hopefully we could do an ok job at identifying the spam, between relays, WoT analysis and even more sophisticated WoT analysis done by DVMs. Thinking more about it relays are pretty incentivised to do good spam prevention. we could select relays we think are doing a good job at it and use them rather than using DVMs too much.
Yeah. I really want to get this in. There a few bugs and resilience changes I have slightly higher on the list.
We've already built the app in React. It's on TestFlight soon. The community will be on Nostr.
Do you have an open repo, I could look at?
We have an Android and web app, API soon, too. The community is open source, the rest we’ve been working on since 2018 and is already a C Corp in DE, so the recommendation app is private repo. A version of the API will be open source. I’ll be doing a demo on HiveTalk soon.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}