 Oddbean new post about login | logout
Oddbean new post about login | logout Spam filters sucked for YEARS. DKIM, SPF and DMARC fixed that, at enormous cost in centralisation, censorship and fragility. I'm hoping we can do better, with modern client capabilities, but I'm aware that we might not succeed for all use cases :-/
We have Bitcoin micropayments, which opens up entirely new possibilities.
Very good point
And we can experiment with WOT Score built from the your followers+broader network, weight stronger if score comes from in network - count mutes - count follows? - count/classify comments?? - count/classify reactions??? Minimum threshold for interaction 🛑/💸 if < lower bound 💁 if close to zero (less interactions, less data to work with) 👍 if > upper bound
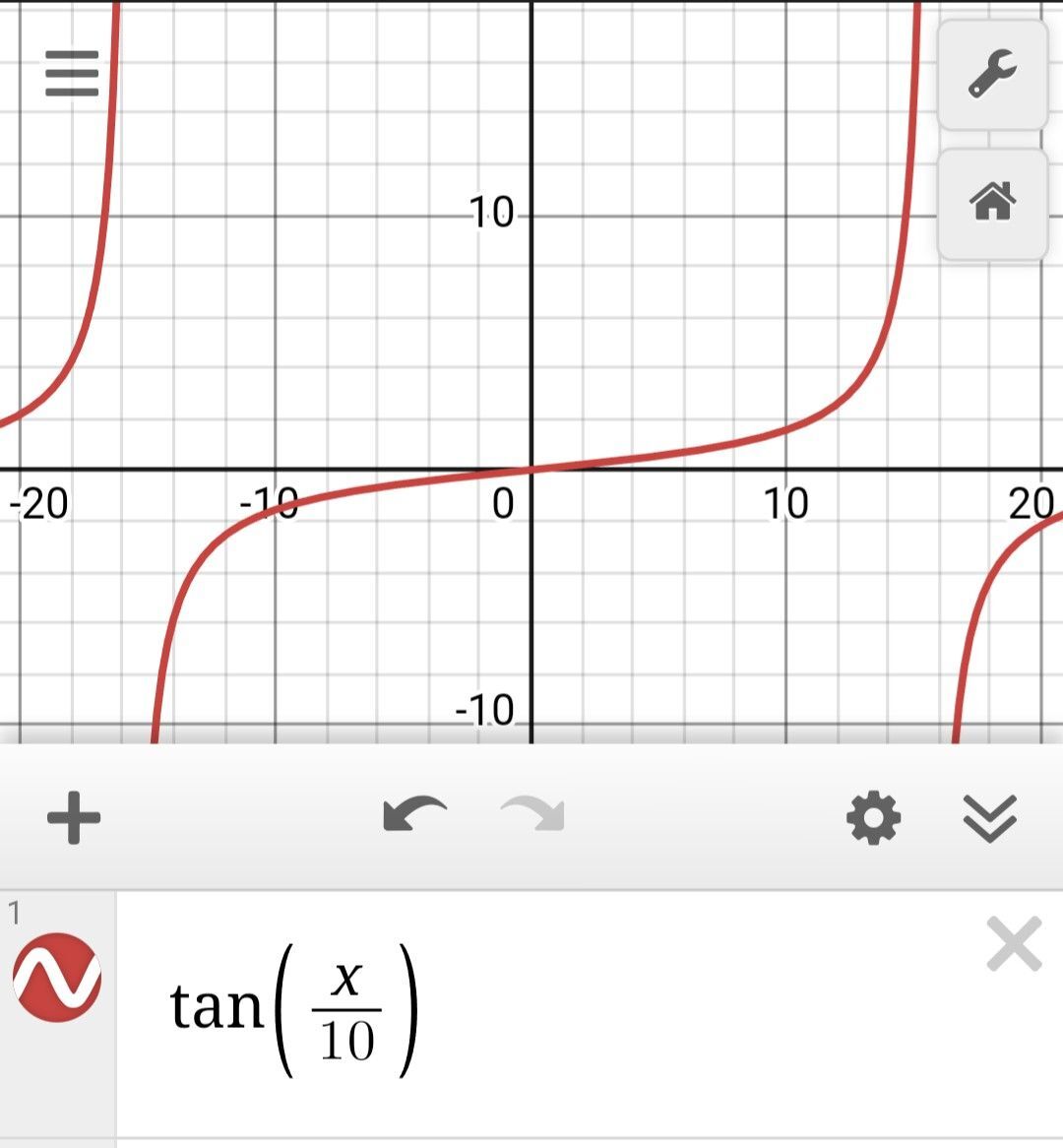
Take the raw count, divide by total number of interactions, throw it into a tan function, scale appropriately and you'll have a WOT that pretty much does that @hodlbod could you give some intuition behind your WOT metric? (follows - ln(mutes)^2)
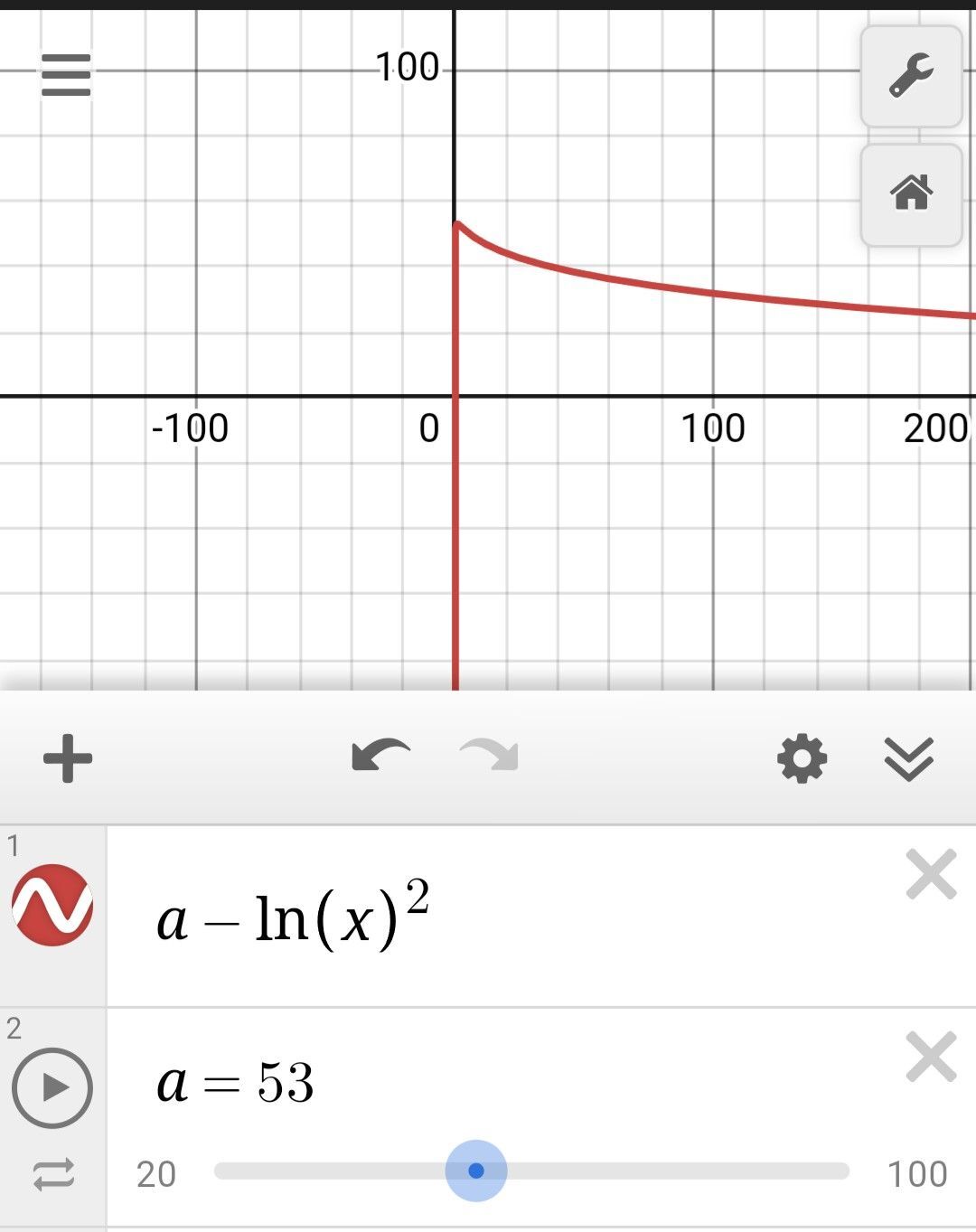
Think WOT is the most straightforward path. Cant stop people from viewing, following, commenting on your public account but you can filter them from your view and put bad actors into a sinkhole where they need a new npub to build trust. Parameters for wot score: nostr:nevent1qqst0r4ky5565r6t8wk9eqgxt3slken8af5z5nlmh6xtx7cckwad85qpz3mhxue69uhhyetvv9ujuerpd46hxtnfdupzphzv6zrv6l89kxpj4h60m5fpz2ycsrfv0c54hjcwdpxqrt8wwlqxqvzqqqqqqyt8lwu5 Multiply by a scaling factor and throw into tan function. At least thats my initial run at it. coracle uses followers- log(mutes)^2 but im not sure where that formula comes from.
I think a formula for this should be standardized
You mean there should already exist a formula that is standardized or that it should be formally defined for nostr as a nip?
m'brain. Tan is interesting, can you explain for non-mathy people like myself?
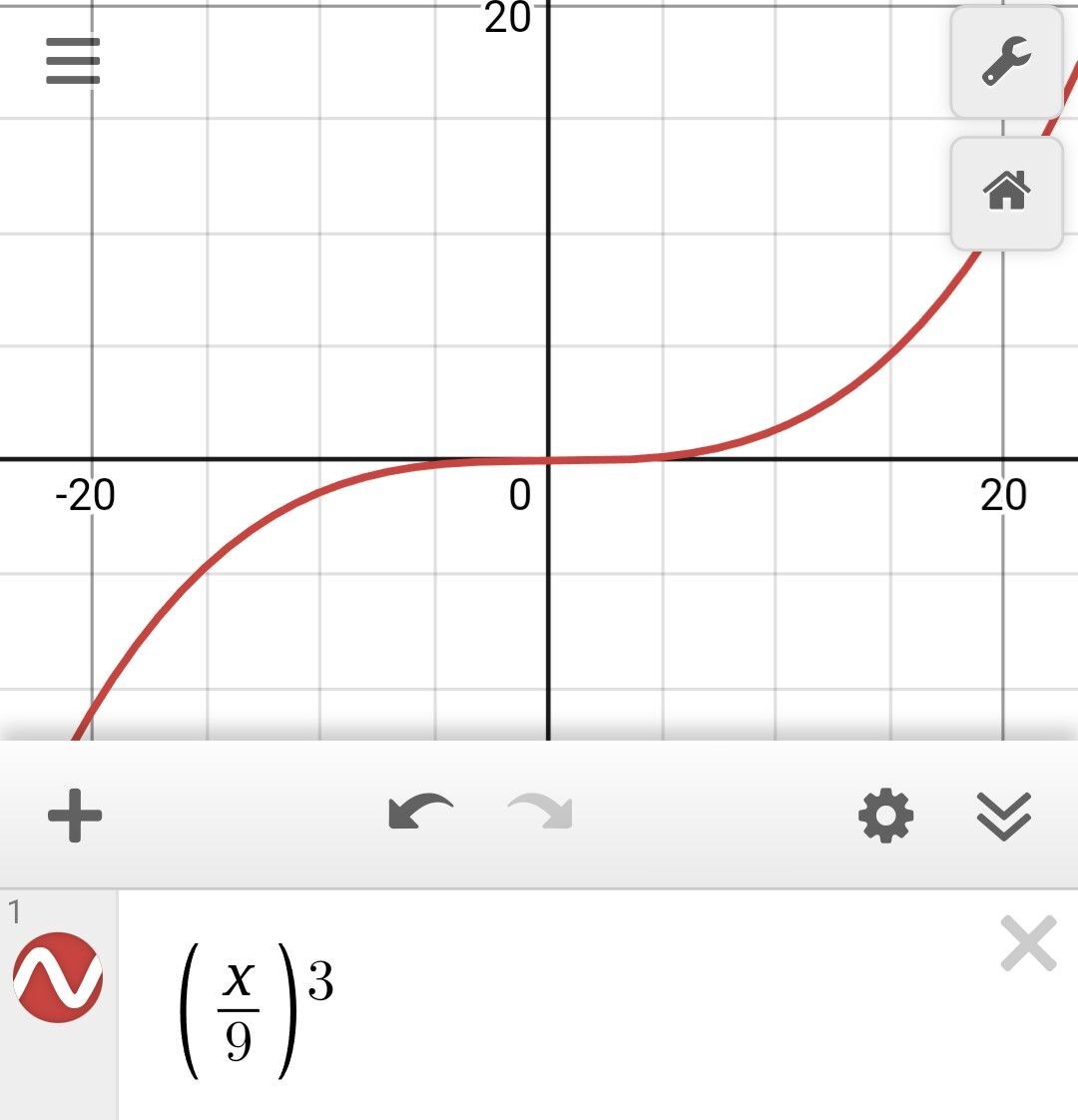
Actually curious about the reasoning for it 😀 We care about some sort of threshold classification, with some sort of "pending"/leniancy state for newcomers. Maybe even a sinkhole point-of-no-return-make-a-new-npub-bitch for spam/noted toxic individuals given your network. A sigmoid is standard practice for classification, but asymptotic bounds of 0 and 1 don't really help those that have been in the game for a while. So we want to classify yes and no, in between state, and also note the very (un)trustworthy individuals. Tan and cubic curves accomplish that. They grow very fast after a certian point. With minimal assumptions, you can just encode every data point as ±1 for positive/negative interactions, and put the average * scaling constant into the function. Or you can weight the interactions by type (mutes>follows> sentiment classification of comments > reaction classification, or weight based on if the points are coming from your follows) and compute the weighted average. https://i.nostr.build/LeV86.jpg https://i.nostr.build/4oG23.jpg https://i.nostr.build/VwVnj.jpg Coracle's WOT formula, where mutes are the argument and follows are the parameter.
Brainstorming WOT nostr:nevent1qqs82gc4rzml32fxkvwpv3d58fa6cqzmh5w7q22tc8tg9xgu7lyzlzspz3mhxue69uhhyetvv9ujuerpd46hxtnfdupzphzv6zrv6l89kxpj4h60m5fpz2ycsrfv0c54hjcwdpxqrt8wwlqxqvzqqqqqqyu499uh
Quite curious at the reasoning or background for the formula vs others. Little brainstorm about using some formulas in this thread. What i'd like out of a WOT is 1) newcomers get leniency, so small number of interactions/ small score is okay 2) below a certian level i dont care, above a certian level i dont care either Think the cubic seems to accomplish that. Forget the mention of tan in this thread though 😅 nostr:nevent1qqs27cam2wcnc8gvr4alja47fm8gf8xvcx3gn4lczj5hhcg9f8f900gpzemhxue69uhhyetvv9ujumn0wd68ytnzv9hxgq3qm3xdppkd0njmrqe2ma8a6ys39zvgp5k8u22mev8xsnqp4nh80srqxpqqqqqqzd2jzu6
I did this method bc it’s quick and easy and I was trying to get it working before I went to sleep last night, but I may add a few options so people can play around with them and see how they differ. Although tbh most of my efforts will be to implement an Influence Score, not a WoT score. That’s the future.
how will that work? is that the idea that people will explicitly state "I trust person A X amount in topic Y?"
The main differences between an Influence Score and WoT scores are that Influence Scores also keep track of context and degree of confidence in the score. If explicit attestations like you describe don’t exist, then we use whatever information is available. If follows and mutes and likes are the best we have, then for each one we infer a score, context, and confidence and feed that into the Influence Score calculation. Example: if Alice “likes” an article by Bob in wikifreedia on Category X, we interpret that as a trust attestation with score: 100, context: Category X, confidence: 5%. I have some posts from a few hours ago saying this in more detail.
The main advantages of Influence Scores are that they’re contextual and they allow us to stop incentivizing people for being “influencers.” So you can find the needle in the haystack, that person who is many hops away from you and has only a few followers but is brilliant in some niche category you’re interested in. The main disadvantage of Influence Scores is they are computationally burdensome, but there are ways to address that problem. https://habla.news/a/naddr1qqxnzdes8q6rwv3hxs6rjvpeqgs98k45ww24g26dl8yatvefx3qrkaglp2yzu6dm3hv2vcxl822lqtgrqsqqqa28kn8wur
I used the Influence Score method rather than WoT scores in a desktop app to curate lists, as described below. What I failed to appreciate when I built that desktop app was that the low quality but abundant proxy data (likes, follows, etc) can be merged with high quality but scarce contextual trust attestations via the method of “interpretation” I just described. Pooling them together is how we overcoming the bootstrapping problem. https://github.com/wds4/pretty-good/blob/main/appDescriptions/curatedLists/overview.md
I did this method bc it’s quick and easy and I was trying to get it working before I went to sleep last night, but I may add a few options so people can play around with them and see how they differ. Although tbh most of my efforts will be to implement an Influence Score, not a WoT score. That’s the future.
how will that work? is that the idea that people will explicitly state "I trust person A X amount in topic Y?"
The main differences between an Influence Score and WoT scores are that Influence Scores also keep track of context and degree of confidence in the score. If explicit attestations like you describe don’t exist, then we use whatever information is available. If follows and mutes and likes are the best we have, then for each one we infer a score, context, and confidence and feed that into the Influence Score calculation. Example: if Alice “likes” an article by Bob in wikifreedia on Category X, we interpret that as a trust attestation with score: 100, context: Category X, confidence: 5%. I have some posts from a few hours ago saying this in more detail.
The main advantages of Influence Scores are that they’re contextual and they allow us to stop incentivizing people for being “influencers.” So you can find the needle in the haystack, that person who is many hops away from you and has only a few followers but is brilliant in some niche category you’re interested in. The main disadvantage of Influence Scores is they are computationally burdensome, but there are ways to address that problem. https://habla.news/a/naddr1qqxnzdes8q6rwv3hxs6rjvpeqgs98k45ww24g26dl8yatvefx3qrkaglp2yzu6dm3hv2vcxl822lqtgrqsqqqa28kn8wur
I used the Influence Score method rather than WoT scores in a desktop app to curate lists, as described below. What I failed to appreciate when I built that desktop app was that the low quality but abundant proxy data (likes, follows, etc) can be merged with high quality but scarce contextual trust attestations via the method of “interpretation” I just described. Pooling them together is how we overcoming the bootstrapping problem. https://github.com/wds4/pretty-good/blob/main/appDescriptions/curatedLists/overview.md
how will that work? is that the idea that people will explicitly state "I trust person A X amount in topic Y?"
The main differences between an Influence Score and WoT scores are that Influence Scores also keep track of context and degree of confidence in the score. If explicit attestations like you describe don’t exist, then we use whatever information is available. If follows and mutes and likes are the best we have, then for each one we infer a score, context, and confidence and feed that into the Influence Score calculation. Example: if Alice “likes” an article by Bob in wikifreedia on Category X, we interpret that as a trust attestation with score: 100, context: Category X, confidence: 5%. I have some posts from a few hours ago saying this in more detail.
The main advantages of Influence Scores are that they’re contextual and they allow us to stop incentivizing people for being “influencers.” So you can find the needle in the haystack, that person who is many hops away from you and has only a few followers but is brilliant in some niche category you’re interested in. The main disadvantage of Influence Scores is they are computationally burdensome, but there are ways to address that problem. https://habla.news/a/naddr1qqxnzdes8q6rwv3hxs6rjvpeqgs98k45ww24g26dl8yatvefx3qrkaglp2yzu6dm3hv2vcxl822lqtgrqsqqqa28kn8wur
I used the Influence Score method rather than WoT scores in a desktop app to curate lists, as described below. What I failed to appreciate when I built that desktop app was that the low quality but abundant proxy data (likes, follows, etc) can be merged with high quality but scarce contextual trust attestations via the method of “interpretation” I just described. Pooling them together is how we overcoming the bootstrapping problem. https://github.com/wds4/pretty-good/blob/main/appDescriptions/curatedLists/overview.md
I used the Influence Score method rather than WoT scores in a desktop app to curate lists, as described below. What I failed to appreciate when I built that desktop app was that the low quality but abundant proxy data (likes, follows, etc) can be merged with high quality but scarce contextual trust attestations via the method of “interpretation” I just described. Pooling them together is how we overcoming the bootstrapping problem. https://github.com/wds4/pretty-good/blob/main/appDescriptions/curatedLists/overview.md
{kind=link}
{kind=link}
{kind=link}