 Oddbean new post about login | logout
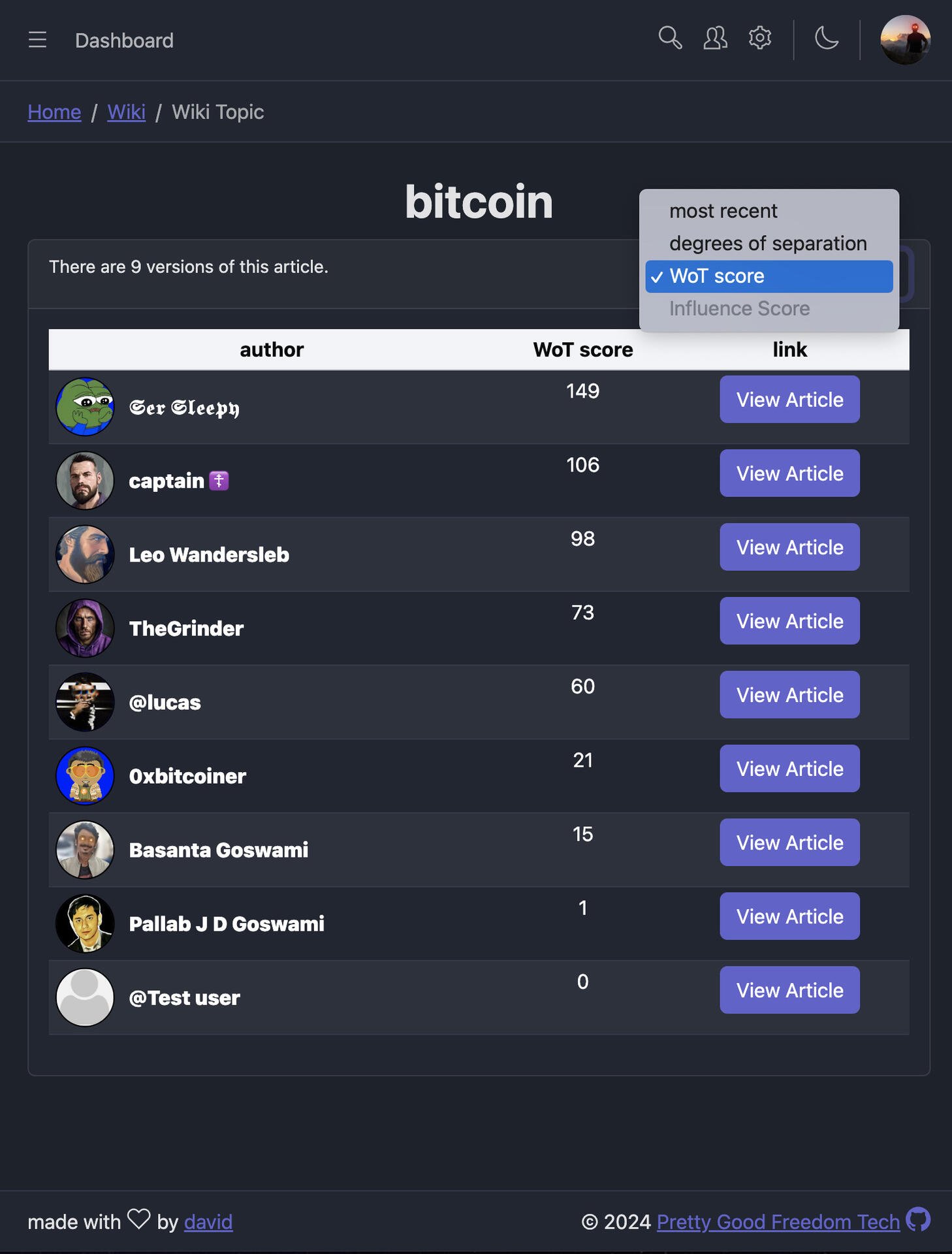
Oddbean new post about login | logout Stratification of wiki articles: - chronologically - degrees of separation from me - WoT score - next up: contextual Influence Score https://image.nostr.build/5f90783b438eaa042da31dddcea696ac878511c3dfcf25514c405977c0267eae.jpg
WoT score for wiki is here!! @hodlbod @jb55 @PABLOF7z
Curious about the formula used to calculate 👀
Same formula as coracle except I haven’t worked in the mutes part of the formula yet. Basically, the number of profiles in the intersection of the set of my follows and your followers is your WoT score. Still kinda a popularity contest, which is why we need Influence Scores.
Quite curious at the reasoning or background for the formula vs others. Little brainstorm about using some formulas in this thread. What i'd like out of a WOT is 1) newcomers get leniency, so small number of interactions/ small score is okay 2) below a certian level i dont care, above a certian level i dont care either Think the cubic seems to accomplish that. Forget the mention of tan in this thread though 😅 nostr:nevent1qqs27cam2wcnc8gvr4alja47fm8gf8xvcx3gn4lczj5hhcg9f8f900gpzemhxue69uhhyetvv9ujumn0wd68ytnzv9hxgq3qm3xdppkd0njmrqe2ma8a6ys39zvgp5k8u22mev8xsnqp4nh80srqxpqqqqqqzd2jzu6
I did this method bc it’s quick and easy and I was trying to get it working before I went to sleep last night, but I may add a few options so people can play around with them and see how they differ. Although tbh most of my efforts will be to implement an Influence Score, not a WoT score. That’s the future.
how will that work? is that the idea that people will explicitly state "I trust person A X amount in topic Y?"
The main differences between an Influence Score and WoT scores are that Influence Scores also keep track of context and degree of confidence in the score. If explicit attestations like you describe don’t exist, then we use whatever information is available. If follows and mutes and likes are the best we have, then for each one we infer a score, context, and confidence and feed that into the Influence Score calculation. Example: if Alice “likes” an article by Bob in wikifreedia on Category X, we interpret that as a trust attestation with score: 100, context: Category X, confidence: 5%. I have some posts from a few hours ago saying this in more detail.
The main advantages of Influence Scores are that they’re contextual and they allow us to stop incentivizing people for being “influencers.” So you can find the needle in the haystack, that person who is many hops away from you and has only a few followers but is brilliant in some niche category you’re interested in. The main disadvantage of Influence Scores is they are computationally burdensome, but there are ways to address that problem. https://habla.news/a/naddr1qqxnzdes8q6rwv3hxs6rjvpeqgs98k45ww24g26dl8yatvefx3qrkaglp2yzu6dm3hv2vcxl822lqtgrqsqqqa28kn8wur
I used the Influence Score method rather than WoT scores in a desktop app to curate lists, as described below. What I failed to appreciate when I built that desktop app was that the low quality but abundant proxy data (likes, follows, etc) can be merged with high quality but scarce contextual trust attestations via the method of “interpretation” I just described. Pooling them together is how we overcoming the bootstrapping problem. https://github.com/wds4/pretty-good/blob/main/appDescriptions/curatedLists/overview.md
it's been part of wikifreedia since version 0.0.1 🤷♂️
https://media1.tenor.com/m/Gc-Z0sECWPoAAAAC/the-simpsons-homer.gif
Haha it took me a while to notice the numbers by the name in wikifreedia were WoT scores
so yeah, I ain’t the first to stratify by WoT. But I will be the first to stratify by Influence. https://habla.news/a/naddr1qqxnzdes8q6rwv3hxs6rjvpeqgs98k45ww24g26dl8yatvefx3qrkaglp2yzu6dm3hv2vcxl822lqtgrqsqqqa28kn8wur
{kind=link}
{kind=link}