A Bitcoin node will detect bugs in the matrix
since I'm not seeing any serious memory or disk issues, and assuming there are no bugs in bitcoin-core, I wonder if my bitcoin node is getting hit by cosmic rays and bits are getting flipped every now and then, leading to leveldb checksum errors.
I looked into ECC ram but I may need to build a home server, since it's not common in desktops motherboards.
Is this is why you’ve been going on about ecc memory @semisol ? I found a post about it from greg maxwell 10 years ago as well, saying all his non-laptop machines use ecc memory:
https://www.reddit.com/r/Bitcoin/comments/2jpk54/risks_of_running_bitcoin_client_on_a_computer/cle3qyb/ nostr:note1ktns7scrqr00h9a400eajn8k23hcxzzp35syfr7j4tvzjkdpjjdsj4z0sf
I run ECC RAM on my hard nodes
gonna have to setup a server rack in my house @Alex Gleason 🐍🚬
i haven't had a rack in my house in a decade... i could be persuaded though...
ryzen supports ecc
Need motherboard support though which is rare for consumer motherboards
I read up you need a ryzen pro apu
I have bought 2 random ASUS boards, one meant for “professional use” and one meant to be lower end (B)
Both work
It is detected as ECC too.
G series CPUs don’t support it don’t ask how I know (tried to add ECC RAM to a system with one) and it didn’t detect as ECC
It is supported but not “validated” (don’t blame us if it doesn’t work) for consumer platforms
/r/homelab sends their regards
Doesn't need to be a power hungry monster homelab though, IIRC some of the newer Lenovo thinkcentre tiny nodes support ECC and have two NVME slots
In many years I've never had a core edition leveldb corruption without a no-raid disk failure (bad sectors)
Yeah time to get serious about this. Gonna do a proper zfs raid and ecc setup
Yes.
I have never had a corrupt DB with ECC memory, even with a few hard power cuts. I use RAID 1, though not with checksumming (mdadm) so about 50% of the time any issues should come up with disks if any.
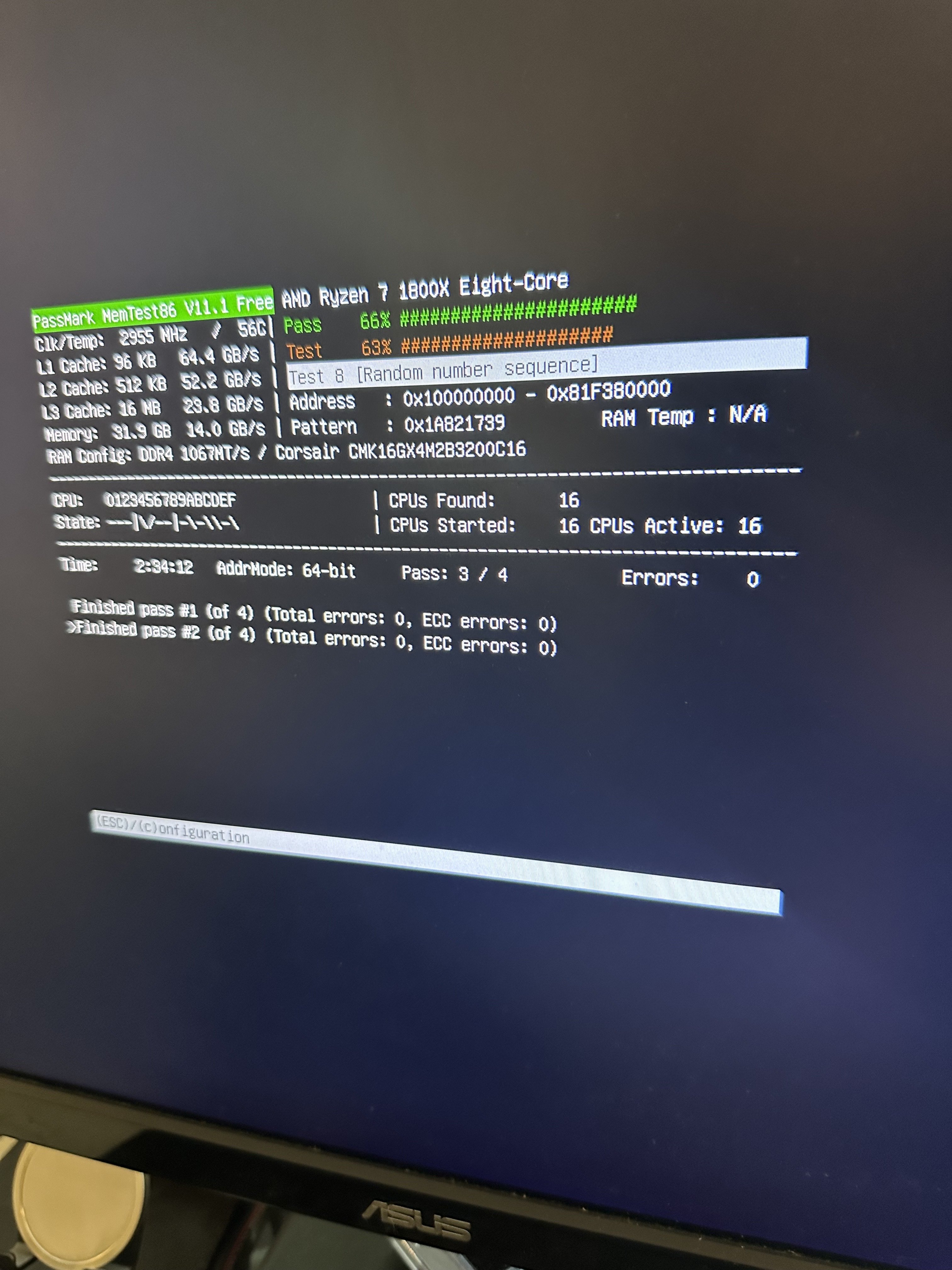
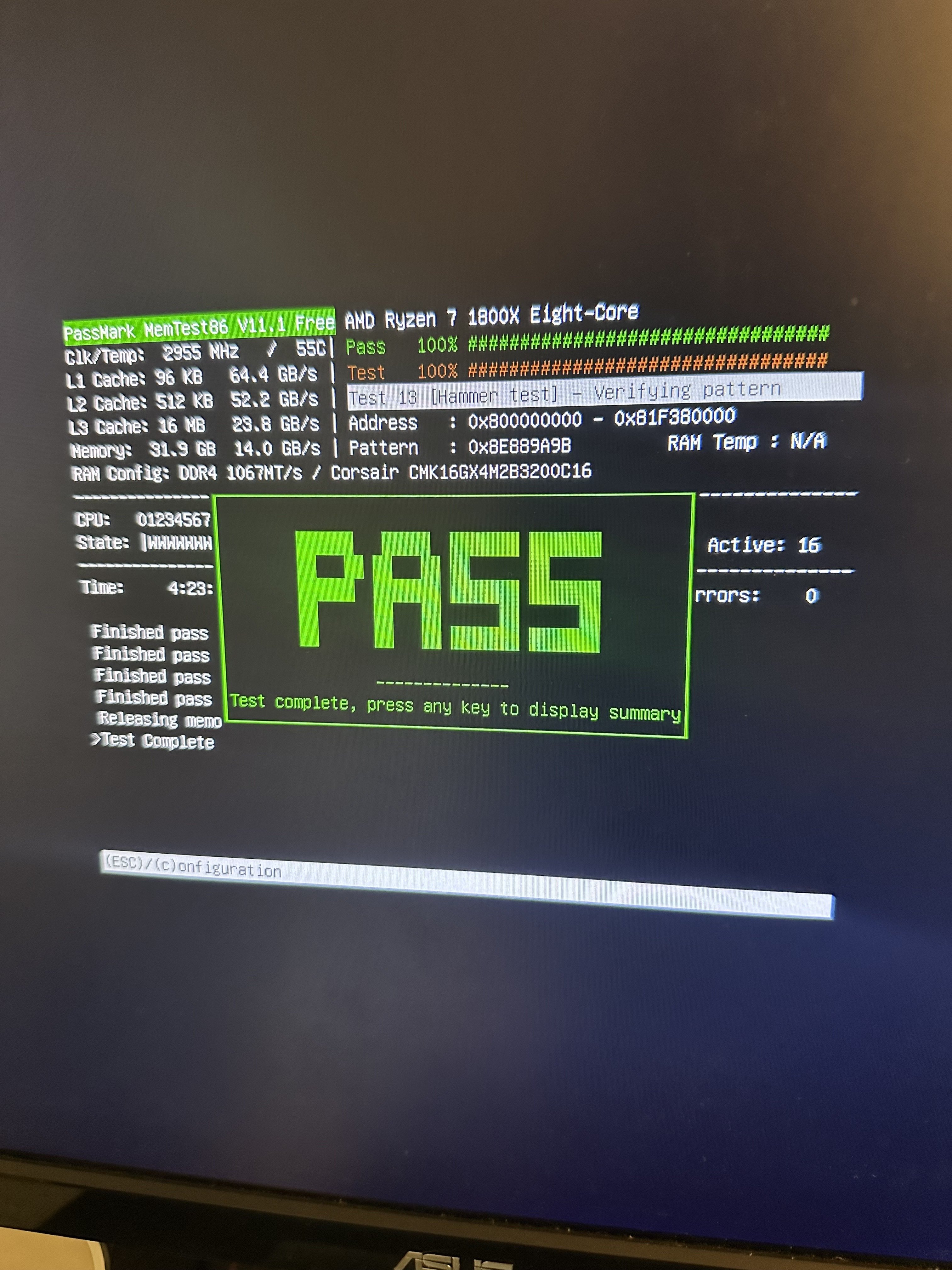
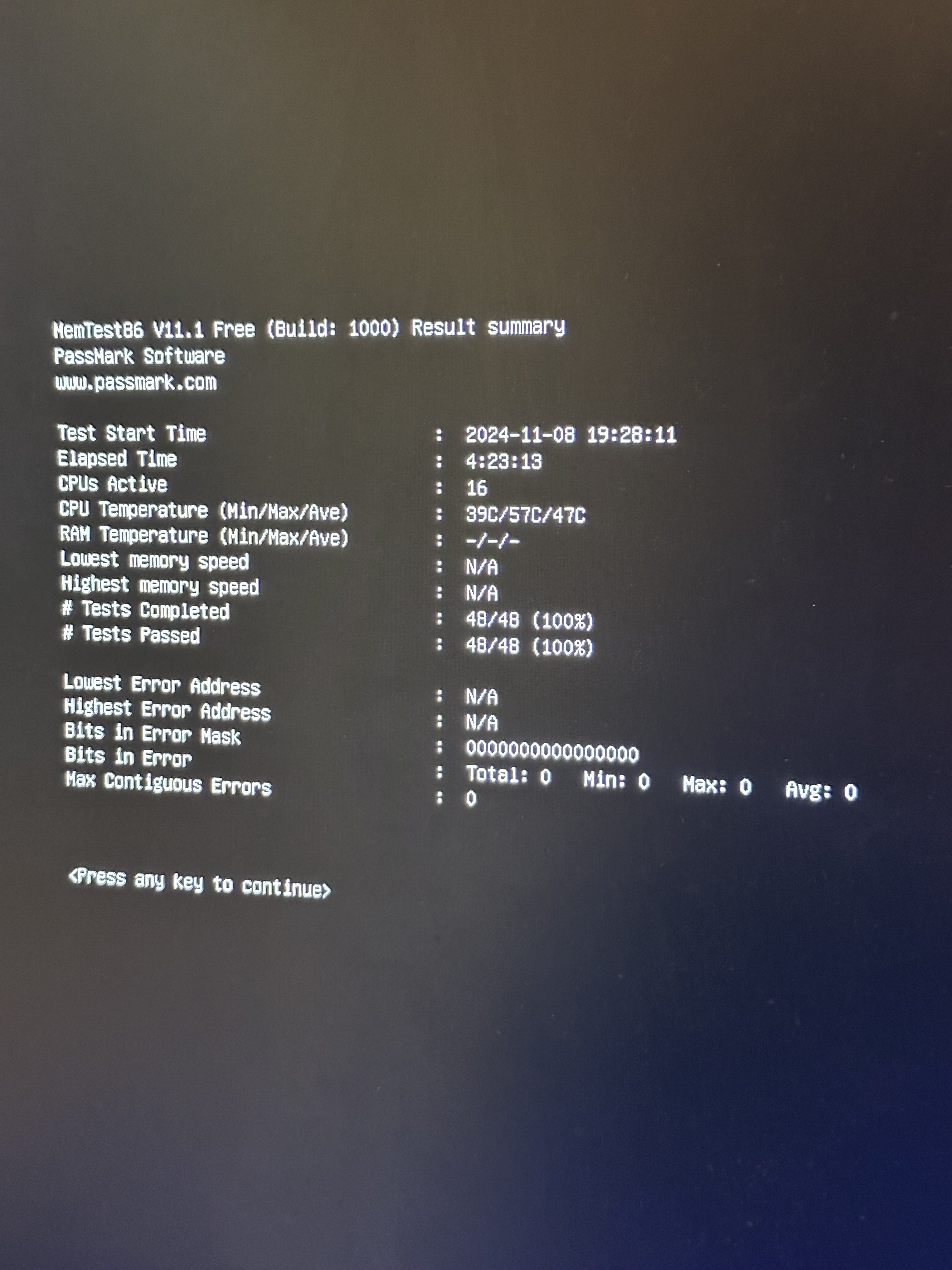
You’re more likely hitting hardware issues that only crop up when running the machine hot. Try running y-cruncher and memtest. Similarly try testing your disk (don’t know any applications that test if it corrupts at high rate, I know they exist tho)
Maybe but i’m never really running this machine hot
i already tried to convince Will of this a few days ago, don't bother
nostr:nevent1qvzqqqqqqypzqz4rnedwlxdqqznmmv95ny2cey4uf23qldjexxjj6p2mt6mdlaecqy28wumn8ghj7mn0wd68ytncxpnzummjvuhszythwden5te0dehhxarj9emkjmn99uqzplvg592v9d62fx4qc3zsuv2h2sml4x98kenrm4hf3e4kekfr0t3m02ylks
Nothing yet… running hot as well. https://i.nostr.build/ERa0xSlAk8elJIQv.jpg
I have two nodes. About 7 days ago, one started crashing every 15-20 hours. That one’s on a raspberry pi 4 with 1tb ssd. The errors are always i/o related. df -h says I have 147gb available. But thinking the ssd is going down. The other node is on Debian and hasn’t had any problems.
yeah I thought it was my drive so I got a new ssd but still having issues. ran tests on that and didn't find anything. trying memtest now.
i'd still be kind of interested in a copy of the corrupted state to see what kind of glitch this is
it just happened again so I can send it
i assume it's another corruption in the chainstate ?
most useful would be to zip up the entire chainstate dir i think (i'm not sure just the one corrupted ldb file will tell much)
yeah chainstate again
not sure what to test next https://i.nostr.build/uQ19fvhzp9LcK1rc.jpg https://i.nostr.build/DtM2hiS379ZZhFhP.jpg https://i.nostr.build/MXBTUyRSN5dENt9v.jpg
what are you using for storage?
was using a hdd, switched to a 4tb ssd recently. I suspect it was due to a low dbcache (32) value but not sure yet
did not see until after that you swapped storage. if you do in fact have an intermittent hardware problem the best way in my experience is to swap parts where you can. since you have the storage out of the way, if you have multiple memory modules I would run one at a time and see how that turns out
You may want to keep an eye on uptime to be sure something isn’t hard power cycling the host, and dmesg to be sure the bitcoind process isn’t getting OOM killed.
I’ve had issues with the later on an RPI4. JSON-RPC calls from Fulcrum or Electrs syncs also seem to be able to use an unbounded amount of memory…
I think ungraceful stops of the bitcoind process at the right time can cause the chainstate DB to come unsynced from the blockchain DB in ways that require reindexing. The really bad throughput of the RPi4’s USB3 ports for block storage may exasperate this
This machine is on a UPS and doesn’t ever randomly restart. It’s never unstable. I don’t run it hot. If it can get corrupted from ungraceful stops then thats a bug.
56C isn’t hot? Memtest generally doesn’t get a CPU hot, just a bit warm.
The Udoo Bolt Gear mini PC supports ECC RAM , that’s why I got one 3 years ago and it’s been running non stop ever since. Silent , powerful. Not super cheap but a reasonable price for what you get
You are probably experiencing memory corruption or something similar without noticing it.
The only times I've ever had a leveldb database get corrupted were due to bad memory. I spent a fair bit of ₿ upgrading my desktop to ECC memory a few years ago due to a run-in with bad memory that corrupted files.
I’ve had many bad memory issues in the past and it usually always leads to system instability. If it is memory it must be a very minor issue that somehow doesn’t cause anything else to crash.
It's very easy for minor memory issues to result in disk corruption rather than overall system instability. You just need something like a single bad bit that only shows up sometimes, eg while hot as nostr:nprofile1qqsr6tj32zrfn7v0pu4aheaytdnnc6rluepq73ndc2tdjzus34gat9qpz4mhxue69uhhyetvv9ujuerpd46hxtnfduhswulwwv pointed out.
Hmm will run more tests to confirm
Write a memory test program that stores 4092 bytes and a CRC
memtest86 does this more thoroughly… ive always used that in the past
You want real workloads
Yeah but its harder to test every physical address, isn’t that the point
Due to interleaving and similar you already mostly achieve that
Memtest doesn’t tend to get your CPU hot, though. Different things can fail at different utilization levels…
There was that prime-something program i remember using a long time ago for that, not sure if there are more modern solutions
ycruncher?
I remember prime95 but maybe that was like 20 years ago
damn im old
whatever type of error you are having must be a more widespread issue than a few pages to be triggered so often
the ideal program would have a small pool it nonstop allocates to and deallocates from and a pool it very slowly checks and rotates allocations in/out
write random data and CRC it as I said
you then want to stop the process and get a debugger if there’s a mismatch and see the physical location along with identifying the RAM module
Prime95 will definitely get a CPU toasty, but you would need to ensure it's running with a mix of large and small FFT and for a while (e.g. hours/days). Small FFT maximizes CPU heat, but isn't the best for finding instabilities working with RAM. Large FFT helps there. In general, I find the overclocking community sometimes works on "vibes" rather than completely proven test methodologies, so take this with a grain of salt.
not that you're overclocking, but that group tends to accumulate tribal knowledge of CPU/RAM stability tests. Hardware can be "fun". A ton of variables. Even things like bios versions can cause instabilities.
 Oddbean new post about login | logout
Oddbean new post about login | logout 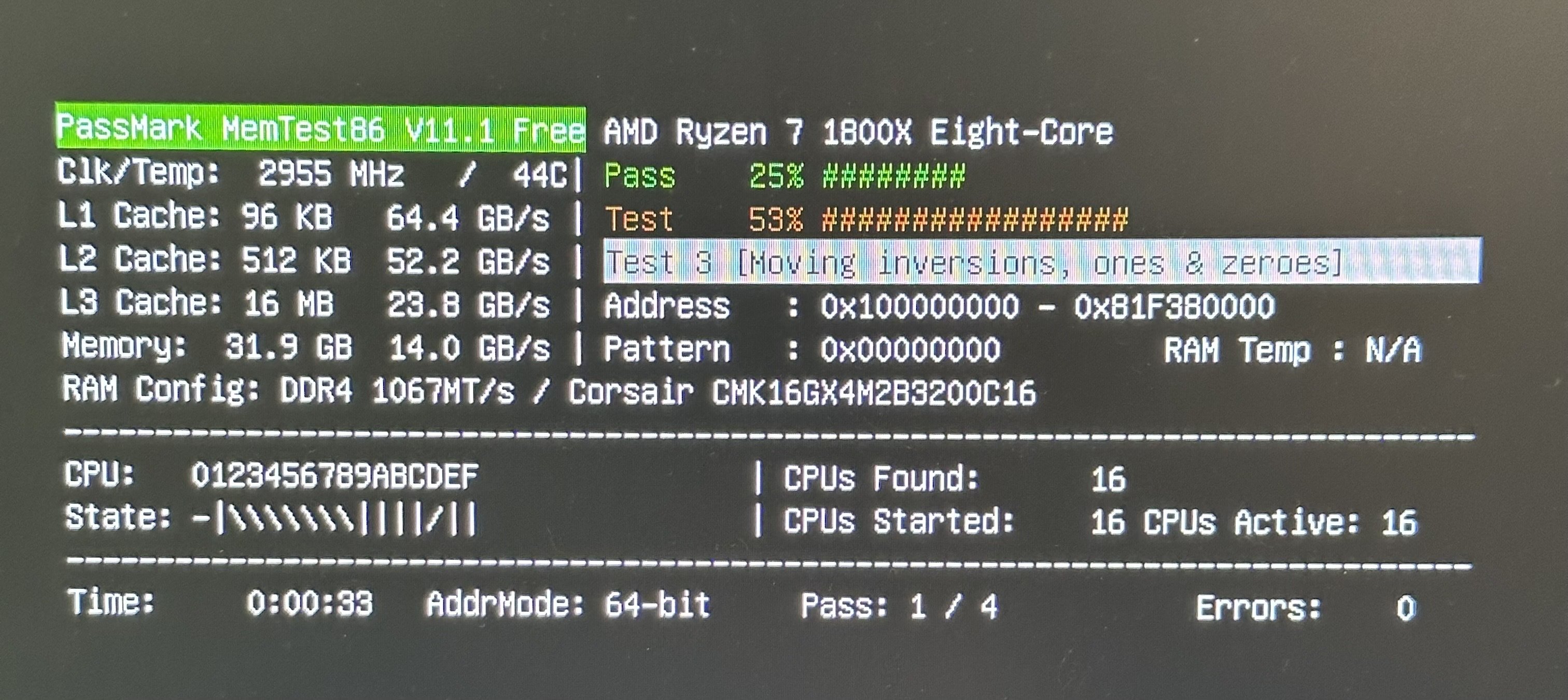{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}