 Oddbean new post about login | logout
Oddbean new post about login | logout Nothing yet… running hot as well. https://i.nostr.build/ERa0xSlAk8elJIQv.jpg
I have two nodes. About 7 days ago, one started crashing every 15-20 hours. That one’s on a raspberry pi 4 with 1tb ssd. The errors are always i/o related. df -h says I have 147gb available. But thinking the ssd is going down. The other node is on Debian and hasn’t had any problems.
i'd still be kind of interested in a copy of the corrupted state to see what kind of glitch this is
it just happened again so I can send it
i assume it's another corruption in the chainstate ? most useful would be to zip up the entire chainstate dir i think (i'm not sure just the one corrupted ldb file will tell much)
yeah chainstate again
not sure what to test next https://i.nostr.build/uQ19fvhzp9LcK1rc.jpg https://i.nostr.build/DtM2hiS379ZZhFhP.jpg https://i.nostr.build/MXBTUyRSN5dENt9v.jpg
what are you using for storage?
was using a hdd, switched to a 4tb ssd recently. I suspect it was due to a low dbcache (32) value but not sure yet
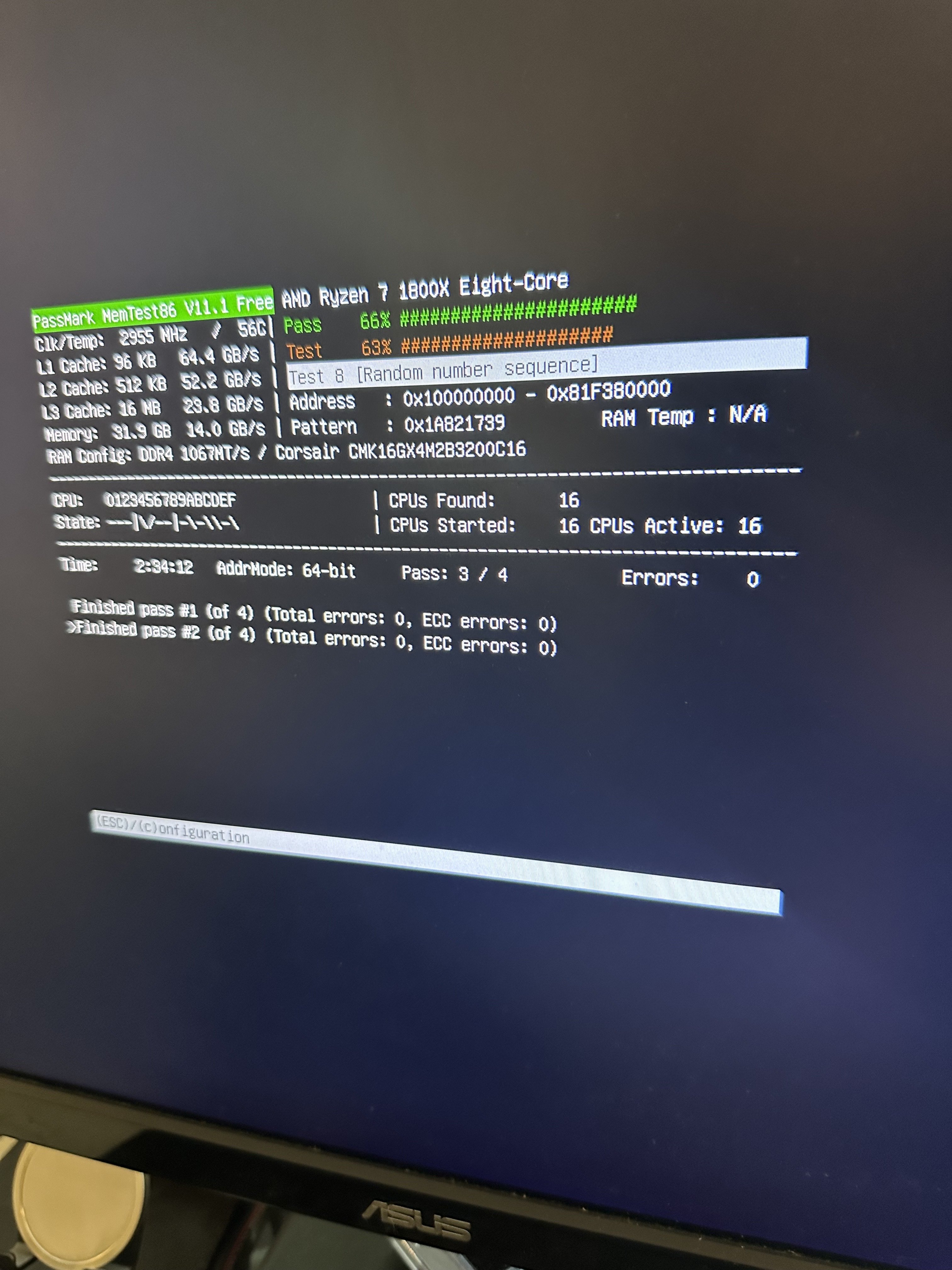
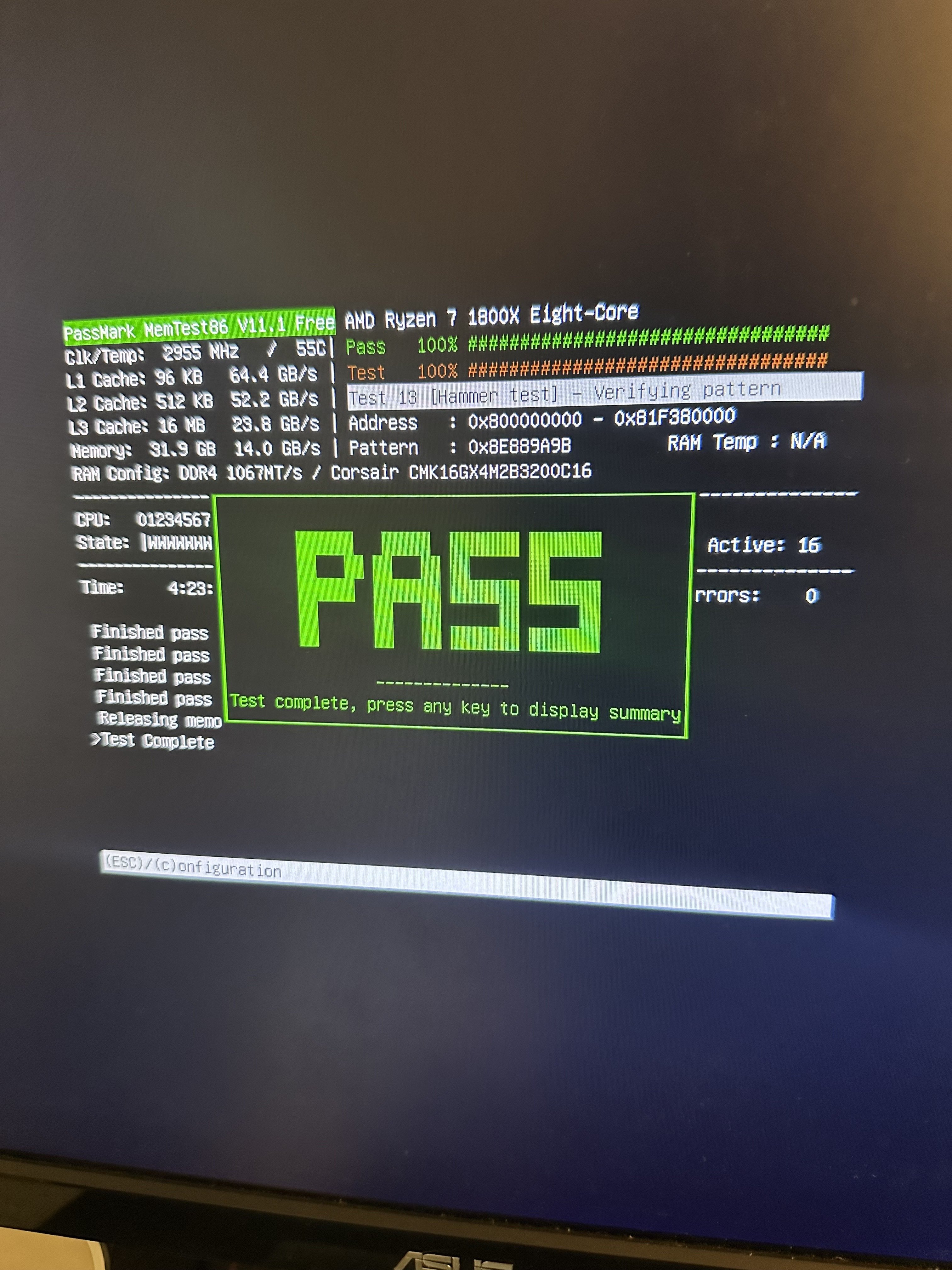
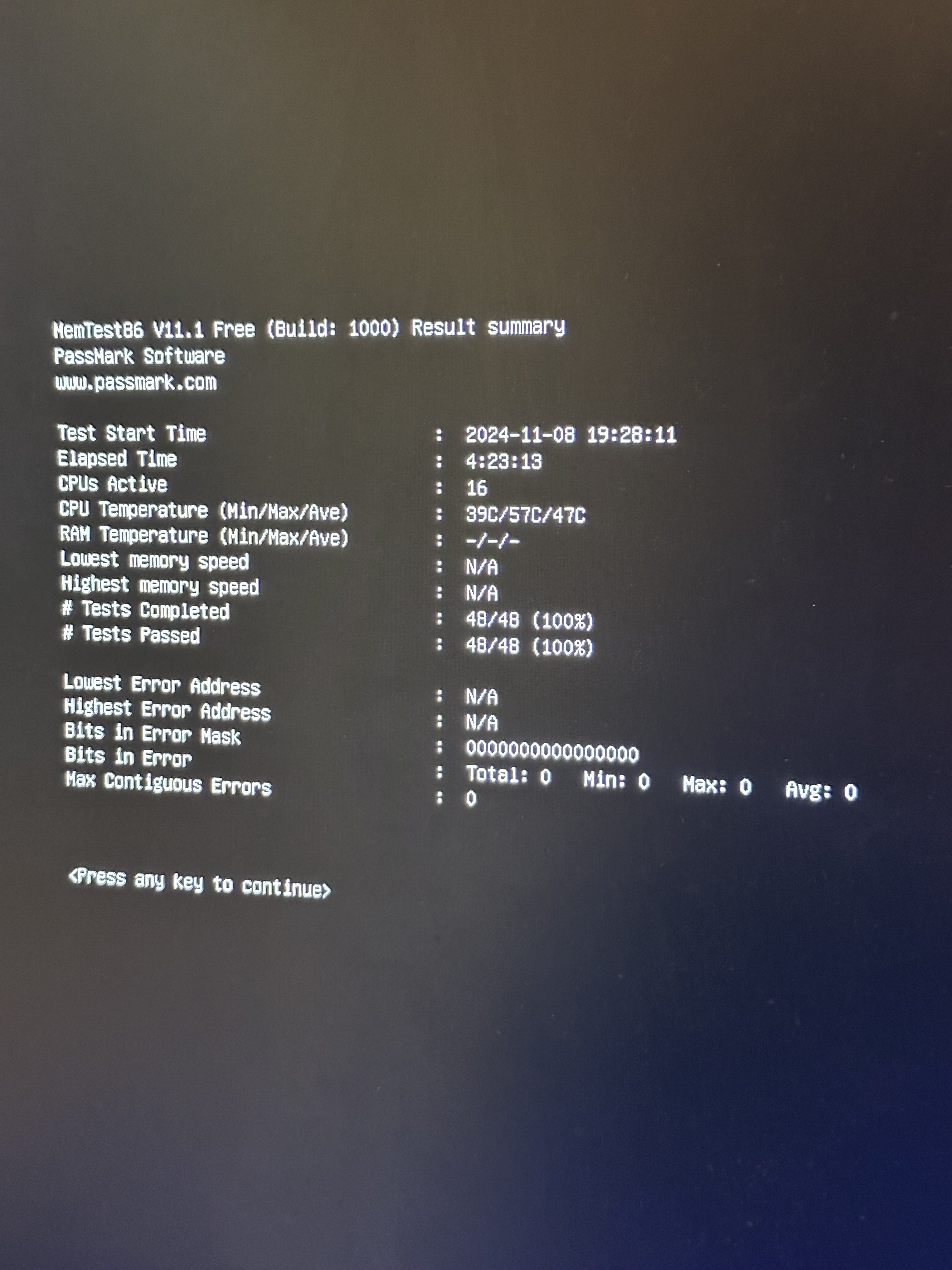
did not see until after that you swapped storage. if you do in fact have an intermittent hardware problem the best way in my experience is to swap parts where you can. since you have the storage out of the way, if you have multiple memory modules I would run one at a time and see how that turns out
You may want to keep an eye on uptime to be sure something isn’t hard power cycling the host, and dmesg to be sure the bitcoind process isn’t getting OOM killed. I’ve had issues with the later on an RPI4. JSON-RPC calls from Fulcrum or Electrs syncs also seem to be able to use an unbounded amount of memory… I think ungraceful stops of the bitcoind process at the right time can cause the chainstate DB to come unsynced from the blockchain DB in ways that require reindexing. The really bad throughput of the RPi4’s USB3 ports for block storage may exasperate this
{kind=link}
{kind=link}
{kind=link}
{kind=link}