 Oddbean new post about login | logout
Oddbean new post about login | logout @jb55 @Vitor Pamplona
i was looking at this same article the other day, been thinking about it...
hugging face always has good blog posts too https://huggingface.co/blog/embedding-quantization#retrieval-speed
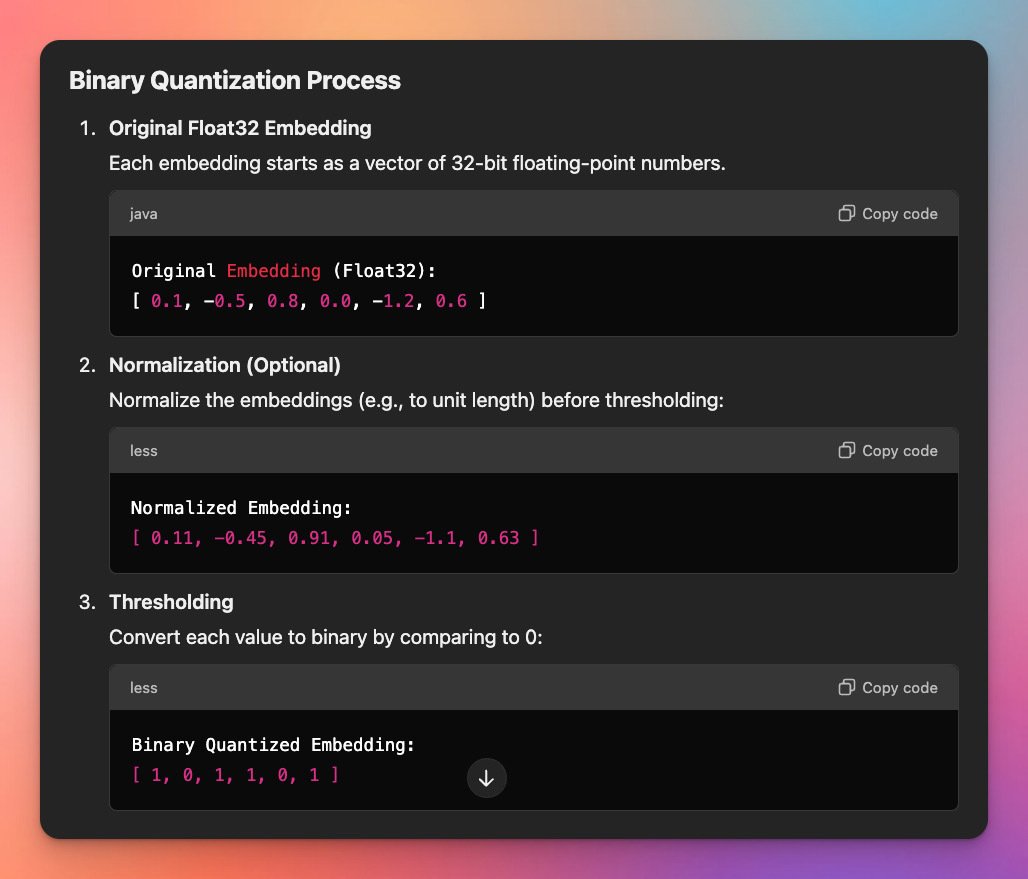
Looks simple enough. I imagine you could even go further with a sparse encoding scheme assuming there are huge gaps of 0 bits, which is probably the case for high dimensional embeddings. https://i.nostr.build/gQtAoY8gxAvtQtNv.jpg
curious if it’s being used anywhere yet
I hear my laptop's fans start whirring around when its making a response, I wouldn't be surprised if its doing something locally first. Either the encoding process (words to tokens) or the retrieval (finding relevant documents from a project)
retrieval maybe? btw have you seen https://www.mixedbread.ai/blog/mxbai-embed-large-v1
{kind=link}