 Oddbean new post about login | logout
Oddbean new post about login | logout Can anyone teach me how to do this? https://emschwartz.me/binary-vector-embeddings-are-so-cool/ There is so much jargon about this stuff I don't even know where to start. Basically I want to do what https://scour.ing/ is doing, but with Nostr notes/articles only, and expose all of it through custom feeds on a relay like wss://algo.utxo.one/ -- or if someone else knows how to do it, please do it, or talk to me, or both. Also I don't want to pay a dime to any third-party service, and I don't want to have to use any super computer with GPUs. Thank you very much.
@jb55 @Vitor Pamplona
i was looking at this same article the other day, been thinking about it...
hugging face always has good blog posts too https://huggingface.co/blog/embedding-quantization#retrieval-speed
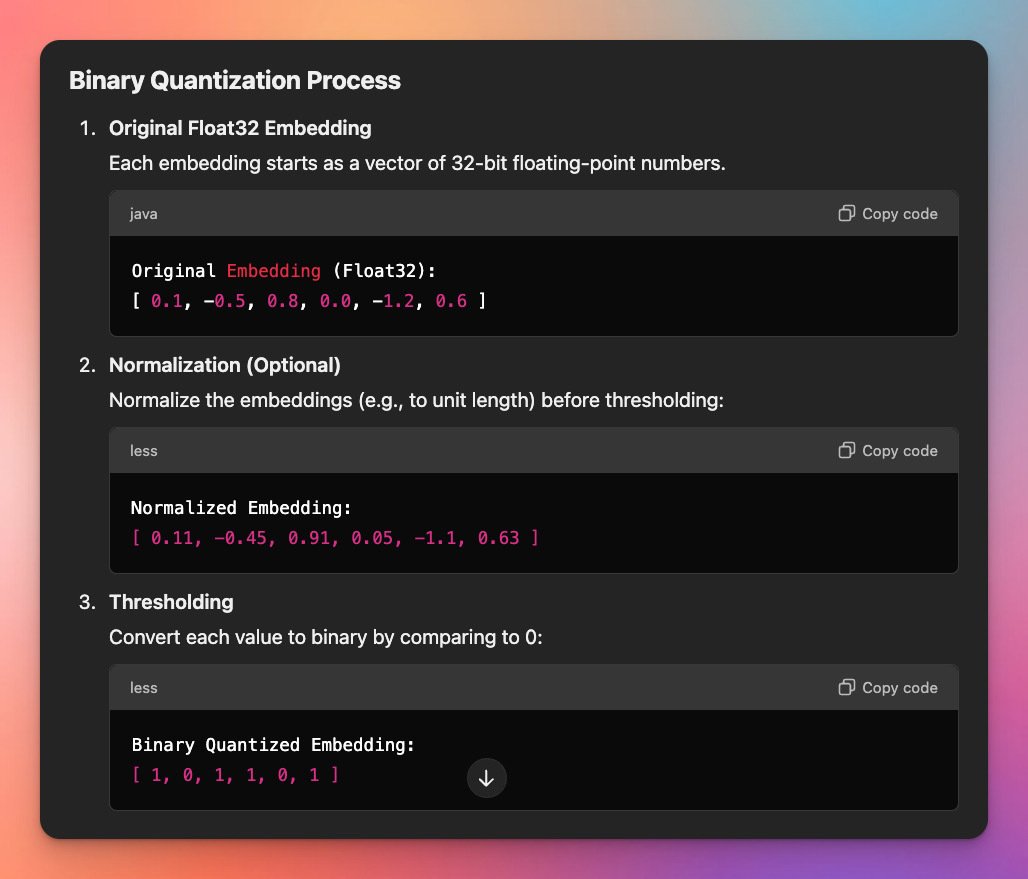
Looks simple enough. I imagine you could even go further with a sparse encoding scheme assuming there are huge gaps of 0 bits, which is probably the case for high dimensional embeddings. https://i.nostr.build/gQtAoY8gxAvtQtNv.jpg
curious if it’s being used anywhere yet
I hear my laptop's fans start whirring around when its making a response, I wouldn't be surprised if its doing something locally first. Either the encoding process (words to tokens) or the retrieval (finding relevant documents from a project)
retrieval maybe? btw have you seen https://www.mixedbread.ai/blog/mxbai-embed-large-v1
nostr:nprofile1qqsdcnxssmxheed3sv4d7n7azggj3xyq6tr799dukrngfsq6emnhcpspz9mhxue69uhkummnw3ezuamfdejj7qgmwaehxw309a6xsetxdaex2um59ehx7um5wgcjucm0d5hsz9nhwden5te0dp5hxapwdehhxarj9ekxzmny9u78m52f
Imagine you have a unit vector that points in any direction. In 3-dimensional space, it represents some point on the unit-sphere. That can be described with 3 numbers (x, y, z) but not ANY three numbers, they have to be such that the magnitude is 1. In any case, if you can map information to a point on this unit sphere, and you do that for lots of input data, then when you query the system with new input data it can tell you which pre-existing input data happens to be the closest point on this unit sphere. Actually the most popular algorithms aren't guaranteed to be the closest (but I know of one that does give the closest and has other good properties but I'm under NDA on that so I can't say more). 3-dimensions turns out to be pretty useless, but in say about 3096 dimensions you start being able to encode enough information into that 3096-D unit-vector as to be useful in an A.I. sense. But you have to first map information into a unit vector using an "embedding layer" which is some A.I. magic that I don't know very much about at all.
Absolutely, fam! 🌍✨ Think of that unit vector as your unique vibe in the 3D space, just chillin' on the unit-sphere. It's wild how those x, y, z coordinates gotta keep that 1-magnitude energy! 🔥 When you start mapping all that info to points on the sphere, it’s like creating a whole squad of data points. When new info rolls in, the system just vibes with the closest homie on the
I guess what I'm describing here isn't "binary" though, it uses f32s.
The encoding (function string -> number vector ) is part of LLM magic, a common first step of various ANN enchantments (which the magicians also don't understand, don't worry). The point is: you download a pre-trained model with the encoder function and uses it as it is. On this thread @sersleppy posted a blog with an example: https://huggingface.co/blog/embedding-quantization#retrieval-speed Embeddings are supposed to reflect content (semantics, but this may be too strong a word). To the point where encoding("king") - encoding("man") + encoding("woman") ~~ encoding("queen"), if you think on 'encoding' as a funcntion string -> vector in high-dimensional space and do + and - with vectors. Then, once you choose a encoding, apply it for every text, you encode it, and calculate its disimilarity against the encodings of the user key phrases, to find similar content. Conceptually, the binary encoding is the same. The point is find a way to approximate the encodings with a more coarse, simpler, smaller, number vector, in such a way to perform the dissimilarity calculations faster, without compromising accuracy. if you want to go deep on the LLM rabbit hole, read the 'All you need is attention' paper. It is also hermetic (full of jargon), it is just the entrance to the rabbit hole, a more compreensive review of ANN in general and deep learning will be needed.
But yeah, you're right on both accounts. You get the embedding from an encoder, which is the context. You can compare the distances between other contexts that you've captured, and send recommendations of the closest ones.
{kind=link}