 Oddbean new post about login | logout
Oddbean new post about login | logout I’m trying to understand the best thinking/knowledge at the moment on how we might serve censorship resistant blobs of media (images/videos). I’ve used nostr.build plenty to host media I share on nostr. It’s great, but obviously represents a single point of failure. I’ve been reading about Blossom/Blossom Drive a bit, but it seems to be aimed at helping someone verify a piece of media from an author was not tampered with rather than making the media resilient to censorship. Is that understanding correct? Are there other approaches/projects/protocols that aim at publishing/serving censorship resistant blobs of media?
Blossom can host media on multiple servers at the same time and proxy requests to whatever host has it . Files are signed with your nip
can't we use IPFS at Nostr?
Testdrive Ditto and Blossom, see the future of nostr https://poster.place https://blossom.poster.place/drive
Blossom is a protocol much like nostr is a protocol. That means that anyone can spin up their own blossom drive. Can be a personal blossom server or they can also spin up essentially what satellite is doing. The question then becomes how easy is it to spin up your own blossom server, and make it publicly discoverable and usable. This is one of the things I believe @Stuart Bowman is working on. When a one click install blossom server exists, everyone can host a Google Drive instance. cc @hzrd149
thanks for sharing! sounds like i should be reading more about Blossom now
I brought this up with hzrd, but this thread might be a good place to get feedback from others and @PABLOF7z, as i'm not aware of a channel to discuss blossom dev, i just see it being discussed every so often: Run Blossom in a webcontainer, as its own server. Webcontainers are able to run nodejs and any npm package in the browser which means integrating one with blossom and a simple server would enable: Hardware agnostic set up, just visit the i.p/url, install it as a progressive app, done. You can start serving your own files, itseld or those of others from the browser. Each client becomes a serving node in the network, while the browser is open. In the monetized environment envisioned by the devs, this means simply opening an instance and being the nearest to need in terms of serving speed, could earn someone zaps ! With this design, Blossom becomes the nostr coordinating daemon, in a sense. I'm not sure i'm explaining it well so i will also describe the user journey: Alice opens their nostr app. They notice a post with a new video from a creator they enjoy. They want to boost(repost) this video but they also think it will be very popular and want to participate in its spread, so they also click the option in their client to help it blossom. This changes context to their local webrowser, which loads up a local copy of the webcontainer hosting the file (blossom). (Since these containers and all associated npm packages install very quickly this happens in seconds.) The context can also switch to an instance they already have running and adds the files hash and address to its serving list. Alice goes back to her nostr client and continues bloom scrolling, with the added potential of earning sats simply for keeping a browser/server open.
No, that’s not it. The hashing is about making the content addressable, which means that the *where* the data, the media, comes from, is non-important. Ok, that gives us the same thing relays give us on nostr, so what? The next piece of the puzzle is the pubkey, tying a blob’s hash to a pubkey allows you to easily retrieve the list of blossom servers that pubkey uses; so when you have a url from a pubkey pointing to server1 as the place to find file with hash1 When server1goes down/censors, you can ask nostr in the same way we use outbox model to find which is the new server for that same pubkey You now have a list of candidates servers that pubkey moved to and a hash; you can just ask for the hash to those servers and voila, maybe you’ll get your file. Since you also can talk about this blob by its hash you can use other tricks to find it or DVMs to go and do the searching for you in exchange for some sats. It really is extremely simple but it works and it’s super powerful.
Is it expected that Blossom servers scrape from other blossom servers for data redundancy?
no, it's not expected, but they can OR, for example, you could have a blossom server in your home that is backing up absolutely everything YOU publish; it doesn't need to do anything special, just listen from events from you and look for referenced blossom URLs. That's it. That's all it needs to do. Say one day your main server rugs you, you automatically have all your prior media fixed. Today we've been discussing the /mirror endpoint, which you can use to accomplish 👇 1. upload file1 to serverA 2. instruct serverB, serverC and serverD to fetch file1 from serverA and keep a copy this could all be done automatically, or not, from your client
To illustrate what this looks like in practice. Here is a demo of an article being rendered in Highlighter, the author used blossom to upload the image. The server went offline, hence the image was broken. “Was” being the key word, within a moment, the image is found using blossom and served from a different server. @note10h28g0x8s22xshtxfst3z7ak4zlhq8ynwke7s6s8ssx0k67g8s7s0engye
ah, i don’t think i was clear that it created a mapping from npub to the blob. that does help a lot, thanks for clarifying. fwiw, this discussion came up in private as i was working with a friend on exploring Highlighter’s long form blogging tool. looks like media is currently uploaded to nostr.build. is Blossom ready for a service like Highlighter to use or still need more development first?
No, it's ready for prime time; I'm working right now on replacing nostr.build with Blossom endpoints-only. It will default to Primal's blossom server but it will be easily configurable. In fact, this very screenshot was uploaded from Highlighter to the Satellite blossom instance, and if it were to go down, it would automagically heal. https://cdn.satellite.earth/eb65cf0b0b6a1ea90180a690661b62acd5429a7419d028bf29ab4174c080cd1d.png
“Automagically” is the best word I’ve heard all year
Okay, let me get this straight. So this image is from a blossom server, but it is linked to directly from a webserver (cdn.satellite.com) So for this to automagically heal, you have to configure known blossom servers on your client so that it will identify missing images from a blossom server and redirect to other blossom servers in order to find the image?
I didn’t know it mapped to an npub either. That’s super cool.
It’s npubs all the way down lol… and that’s probably a good thing. I’ve heard @calle 👁️⚡👁️ noting about npubs to address cashu mints I was talking with someone recently about npubs to be website addresses and I think @PABLOF7z shared something like this today? and now we’re learning from @hzrd149 that Blossom addresses a piece of media with an npub where the underlying serving location can be re-mapped making the media serving more resilient maybe npubs are really about creating an abstraction/mapping layer when accessing any entity, be it person or service?
Yup. 100%. The addressability plus the layers of “how to find stuff related to me” that the protocol already does makes it like the universal join table for nostr data. I’ve been digging in on double ratchets and syncing big groups across devices and, wouldn’t you know, I think npubs are going to solve problems there.
uncoupling a blob from a specific url, and making it locatable anywhere on the network is such a powerful idea
🤝 https://m.primal.net/IUqF.jpg
next youll make relays key addressable and add a dht, voila p2p
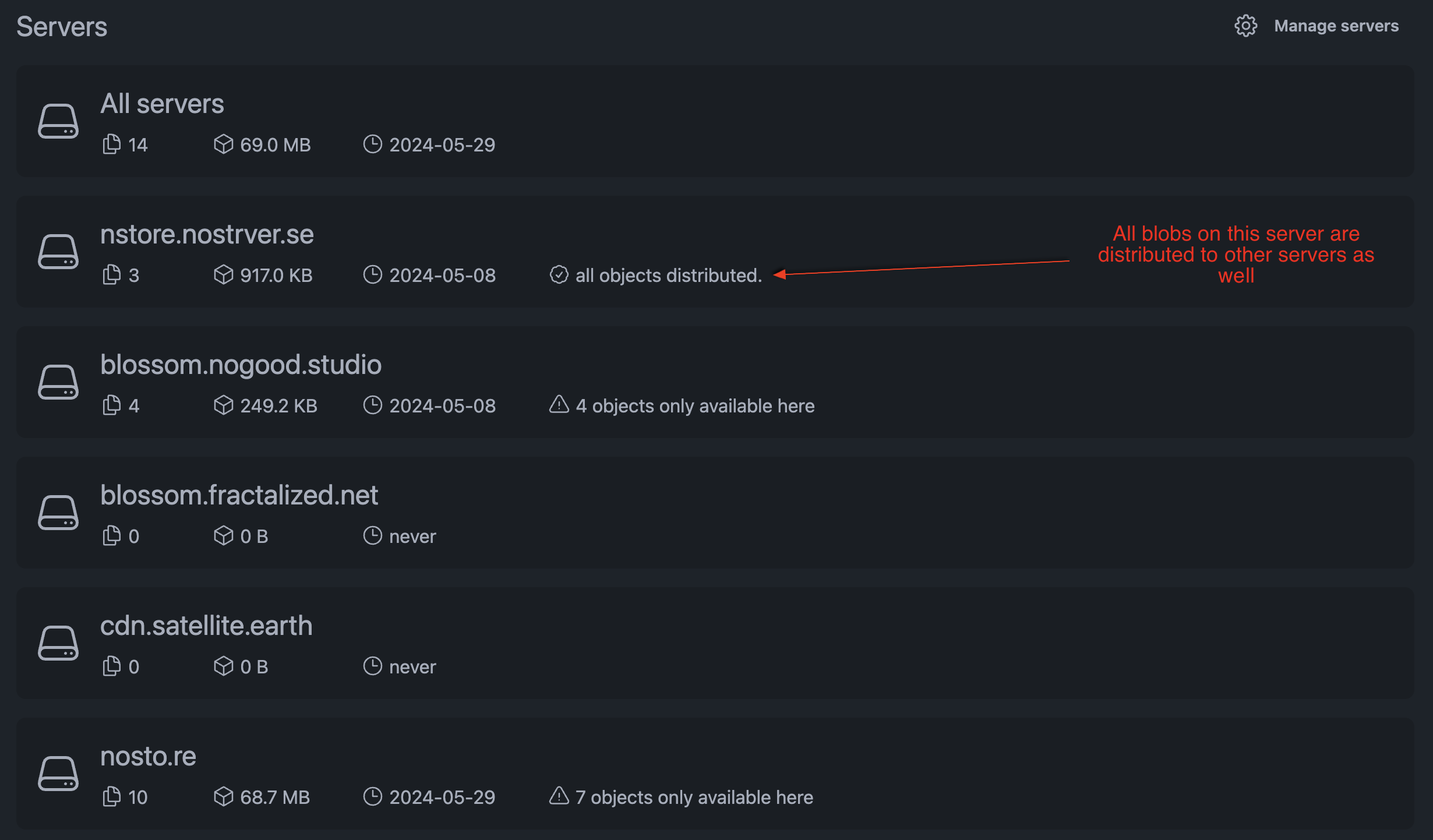
Please have a look at https://bouquet.slidestr.net/ build by @florian There I'm able to connect to multiple Blossom mediaserver and transfer blobs between them. So my blobs can live on multiple mediaserver with the same identifier all signed by my keys. https://shares.sebastix.dev/BeHMfw6D.png
Verifying that a blob is the original is the first step for censorship resistant media and distributed storage. If a server had to check with another server to know if a blob was the original it would never work. While blossom doesn't have any p2p or specific censorship resistant tech in it. I think its "censorship resistant" enough. similar to how nostr events work with relays. There isn't anything in the protocol saying events / blobs must be distributed. but because they can be easily verified, they can be copied to another relay / server without asking anyone. This seems to lead to popular notes ( and maybe blobs ) magically distributing themself throughout the network. and so becoming "censorship resistant" enough
That is one of our goals at https://vaporware.network Dead-easy to run personal servers, including tasks like uncensorable static content serving
INCREDIBLY BULLISH ON BLOSSOM. CONSIDER WATCHING THIS RIP. MAY BE HELPFUL: nostr:note13h9uwmy9w7dqgcdv58nlc0nt43pla3upczrsrdzd06vzqgvkeasqklk5xc
It's possible to use nostr.build and Blossom uploaders interchangeably: https://nostrify.dev/upload/#implementations
You're correct that Blossom/Blossom Drive focuses on verifying the authenticity of media rather than making it censorship-resistant. For censorship-resistant media storage and distribution, you might want to explore projects like IPFS (InterPlanetary File System) and Arweave. Both aim to decentralize data storage, making it harder to censor. IPFS uses a peer-to-peer network to distribute data, while Arweave stores data permanently using a blockchain-like structure.
iroh is a make over of ipfs, pear is the leader in p2p https://github.com/n0-computer/iroh and pears.com
using p2p tech like pear
{kind=link}
{kind=link}
{kind=link}
{kind=link}