 Oddbean new post about login | logout
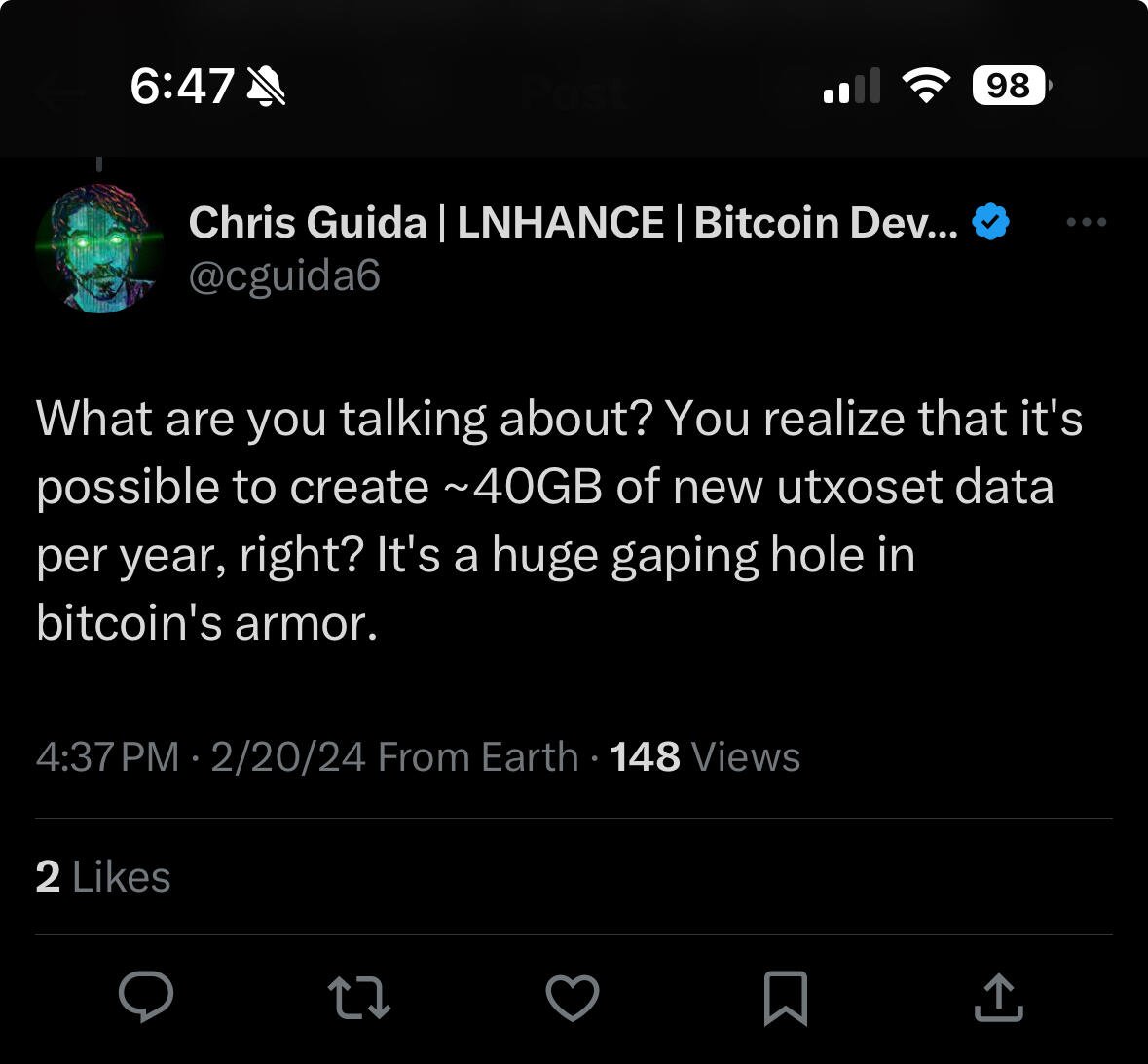
Oddbean new post about login | logout Do you agree with this take from @Chris Guida? https://image.nostr.build/721d6b69dcdd00022454b5a6d06b4ace9941c1230140a497aa20948384f4e88a.jpg
So, 400 GB after 10 years? … Not seeing the problem here since RAID is a thing and Moore’s law is a thing…?
The problem is that the initial sync slows to a crawl when UTXOs are stored on disk rather than in RAM. You can see this effect most clearly in low-resource devices like Raspberry Pis with 4GB of RAM, which used to be able to sync the chain in just a few days, but now take around a month. This has resulted in these devices becoming practically useless as bitcoin nodes, whereas a year ago (when the utxoset was half as large as it is now), they were usable. I consider Raspberry Pis to be the canary in the coalmine wrt UTXO set growth. Although they should probably never have been recommended, we should consider it a failure as a community when a whole class of devices is excluded from participating in the bitcoin network. We need to be making it *easier*, not harder, to run a full node, and I consider this to be the #1 priority of the bitcoin community, as it is already extremely rare to find merchants who run their own nodes. Although most computers can fit 10GB in memory at the moment, if the UTXO set were to expand to 50GB, which it could theoretically do in just a year in an attack scenario, the majority of computers would be unable to fit the UTXO set in memory, and would thus be less and less likely to be able to sync bitcoin in a reasonable amount of time. Obviously 400GB does not fit into RAM unless you are spending tons of money on high-end servers. Let's avoid requiring high-end servers to use bitcoin.
There must be some clever way to compress or summarize and validate the utxo set or like I said Moore’s law can continue and prior to it being a problem large amounts of RAM today will be trivially cheap, fast, and reliable? Or some combination of solutions?
https://zerosync.org/
Is this anywhere close to being production ready? How would a merchant use this?
I dunno. Haven’t looked into it much. @benthecarman do you know anything about the status of ZeroSync?
It can do header validation but not yet able to run it as a full node. Probably pretty far away from that
I think assumeutxo may be the closest thing I have seen to a mitigation, though I haven't seen much movement trying to implement it in a user-friendly way, and of course you still need to be able to do the sync eventually even if your node is usable ~immediately, so you can help bootstrap other nodes.
I wonder if any work has been done with utxo set for selectively deciding which to hold in memory vs disk lookups based on age.
Yes, I have wondered this as well. It would surprise me a lot if *no* work had been done.
1. I haven't had a sync time take a month even on a small raspberri pi. It's about a week, maybe a little bit more. Are you sure these people aren't using old HDD drives instead of an SSD? Or maybe the internet connection is a limiting factor here? Those make a huge difference 2. You are correct that a larger UTXO set makes it take quite a bit longer because of the I/O from disk, but this would be no different if it was literal adoption growth or some BRC20 garbage being shoved into the chain. Which means the only solution is literally to drastically lower the blocksize, or to alter the UTXO model entirely because of this inescapable reality of the system. 3. The baremultisig problem can be gotten around at the node level, by being instantly disregarded after creation. The only UTXOs that contribute to this problem are ones that get spent again, and therefore are involved in future transactions. 4. I completely agree we should be doing everything possible to make it easier to run a node, but the big problem with falling/static node counts isn't the difficulty of running one, its the fact that no one is incentivized to and everyone coming in isn't thinking about network stewardship, they just want their app to work. 5. High fees and ignoring stupid projects that do nothing but shit in the public park that is #Bitcoin are still the only real solution to this problem, imo. We cannot control how people use Bitcoin, and we cannot change the UTXO model (assuming there is even something that could "fix" this issue), which means we need to think about and implement ways to compress the validation of the UTXO set. This was why I mentioned UTREEXO. I also saw you mentioned assumevalid as well. I suspect this can be largely mitigated with a database mechanism rather than any sort of block control or consensus alteration. Would be nice to see people working on this problem more seriously, but I don't think it's our #1 concern. In fact, I think if we could use UTREEXO to get the UTXO set from other nodes immediately and start working with a full node within minutes, while the full validation happens in the background, I think this isn't a drastic concern. (also we get the lucky benefit that Ai is currently causing an *aggressive* funding and focus on an increase in the size of, and lowering of cost for RAM, so at least that is working in our favor) A legit concern ≠ existential crisis
Moore's law is also acting on raspberry pi's: 2012 R.pi 1 256-512MB RAM 2015 R.pi 2, 1GB RAM 2018 R.pi 3B, 1GB RAM 2019 R.pi 4B, 2-8GB RAM 2023 R.pi 5, 4-8GM RAM
Before I comment, can we also please get Mark Goodwin on nostr Too much cry baby shit to sift through with terrible takes on X 😂
Ill try. Mark is the man.
I keep pestering him on X about it 😂 Level headed smart people that can see and imagine a future bitcoin world that every one engages with should be having conversations here as well.
It’s not optimal, but if the UTXO set growing too large was an existential crisis, then there’s simply a fundamental design flaw that’s inescapable. But it’s not. It does mean we probably need some tools to simplify that when the time comes. UTREEXO would be a really good one.
It's an existential crisis nostr:nevent1qqsqmpxcx70gy6nzg57ds6p8nu8cxs8xfmx2lguqvxg40cts9d2v73spzamhxue69uhkummnw3ezuendwsh8w6t69e3xj7szyq5ftsescglnsvvkcrhe3r0xm2pmsw69s0k4l8q7mv99t88v68usqqcyqqqqqqgn8pehe
I tried zapping you @Chris Guida but not sure if your LNURL is up.
Hmm sorry, I don't use Nostr much, I'll see if I can fix it
Responded to the wrong thread. But here is the note nostr:nevent1qvzqqqqqqypzpw08v4rt5pj9dmfsrk0990zflfywwznt7g5zheap4eefgasjqg7uqyghwumn8ghj7mn0wd68ytnhd9hx2tcpz4mhxue69uhhyetvv9ujuerpd46hxtnfduhsqgpcrrhtmcp05zmw3akxvvax5hl8xhkpzghqprhpphhkucls9dpajy3t9kx0
I havent personally done the math to verify this as the rate of potential growth, but it sounds as though its in the right ballpark. The reason given is accurate, and the utxo set size is and has been one of the biggest challenges that need to be tackled.
{kind=link}