 Oddbean new post about login | logout
Oddbean new post about login | logout https://github.com/yukibtc/rust-negentropy
Nice! Do you know what's the difference between this and minisketch
No, I'll try to take a look
From my understanding (I can worng), range-based set reconciliation (negenteopy) are good with small set, while BCH-based (minisketch) works better with large set and provide error correction. Maybe @Doug Hoyte can correct me or add some more info.
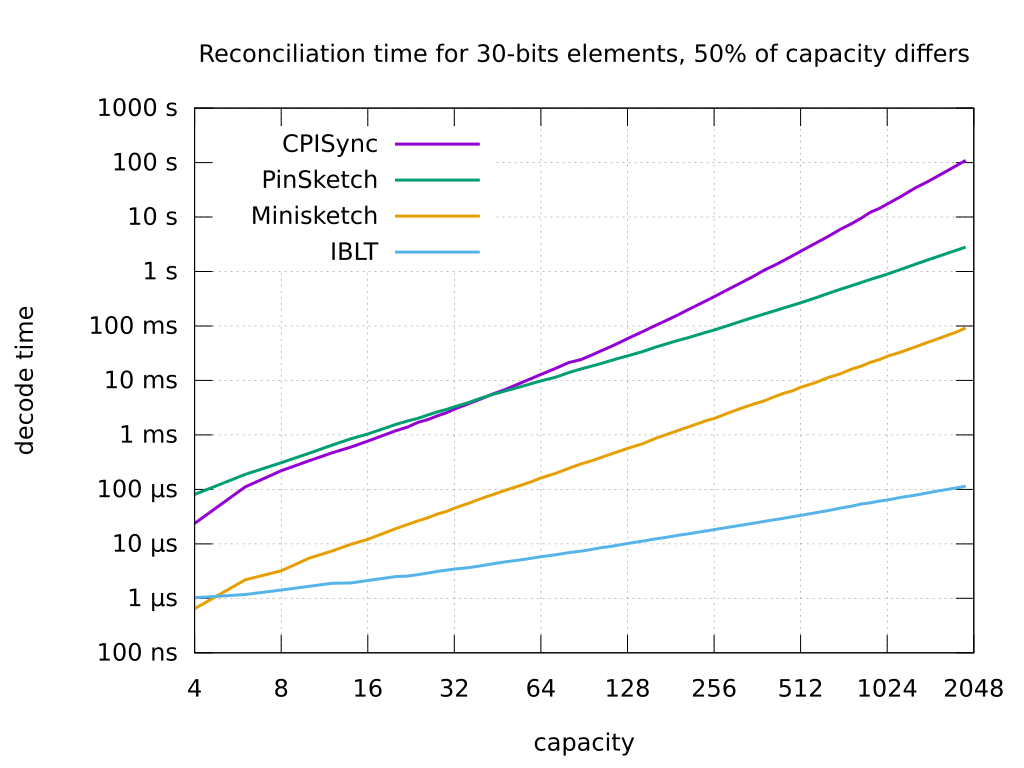
I only have a very rough understanding of how minisketch works, but from what I know it is the opposite. Minisketch is very good with small set sizes -- so good that it approaches the information-theoretic bounds of what is possible, bandwidth-wise. However, look at the first graph on the minisketch site: https://raw.githubusercontent.com/sipa/minisketch/master/doc/plot_capacity.png Here you can see that the CPU time required is exponential in its "capacity" parameter (note the Y axis is log-scale), and will become impractical in the low thousands. The text hints at this too: "For the largest sizes currently of interest to the authors, such as a set of capacity 4096 with 1024 differences". OTOH, negentropy works predictably well into the millions or tens of millions of events. By pre-computing fingerprints as described in Aljoscha Meyer's paper, this will scale to arbitrarily large sizes. Some other downsides that I see with minisketch are that you need to choose an appropriate capacity before you begin the reconcilliation, otherwise it will fail (?). How do you choose that? Also, minisketch's performance depends on the field-size, which I believe is basically how large the IDs being reconciled can be. The largest example shown is 64 bits, which is uncomfortably small if trying to avoid collisions. negentropy by default uses 128 bits, but can scale this arbitrarily high with only linear overhead in bandwidth and CPU. By contrast, negentropy requires almost no tuning. The default parameters I have selected seem to work well for both small and large set sizes, and with small and large symmetric differences between the two sides. I am in the process of adding negentropy support to gensync, which is a general benchmarking framework for set reconcilliation protocols. I'll post any updates about my progress here: https://github.com/nislab/gensync/issues/9
This is awesome, thank you! I'm trying to create a harness for this so we can run it against the test-suite used by the C++ and JS implementations. For example, here's the C++ harness: https://github.com/hoytech/negentropy/blob/master/test/cpp/harness.cpp This is as far as I got: https://gist.github.com/hoytech/96e65fc488fc39c2e782830f38727391 This is pretty much the first Rust code I've ever written, sorry about the bad quality. The problem I'm running into is that the reconcile() and reconcile_with_ids() methods seem to return String. If I understand rightly, Rust strings must be utf-8 encoded right? In the current implementations, the reconcile messages must be in an 8-bit clean medium (or hex encoded). Same with the IDs (since they are typically hash function outputs). In C++ I use std::string because this allows any u8 values (and doesn't care anywhere about utf-8). In JS I allow Uint8Array values *or* hex-encoded strings. Can we make the rust interface standardise on something 8-bit clean? Vec<u8> or some such? Or it's very possible I'm misinterpreting the code here. Any pointers are very much appreciated.
Thank you. I'm still improving and studying better the negentropy protocol. I converted the code from C++ to Rust in basically a day and half (I'm not a C++ dev so some thing could be converted badly) and are there some things to fix/improve. Like, I noticed an unstable performance with reconcilie_with_ids method with a set of 50000 items: it usually took 600 ms the final reconciliation but often it took 2 or 4 secs (executing exactly the same code). Thanks, I'll replace the String with a vector. BTW, I'm planning to release also bindings for some languages (Kotlin, Swift and Python) using UniFFI, like I have done for rust-nostr libraries.
600ms seems too long for that set size. I will take a look at the performance when I have my Rust harness working. Let's make sure it's working the same way as the C++/JS impls first, and then we can see if there any speed-ups. One optimisation I did in the C++ was to ensure that the XORing is always done word-wise, instead of byte-for-byte. In fact, with attention to the alignment, I got the compiler to emit PXOR SIMD instructions to do multiple words in a single instruction. That's very cool about the UniFFI bindings, I'm looking forward to it!
Performance issues should be solved now: reconciliation of 1 million ids took ~400 ms
Found another optimization: 1 million ids reconciled in ~100 ms
Awesome! I made a bit of progress on connecting the test harness, but I found an area where the implementations differ. I'm going to keep looking into it, but I wrote up what I've found so far here: https://github.com/yukibtc/rust-negentropy/issues/1
Nice, will look into amd optimizations in the damus+nostrdb version. Not sure if you’ve seen nostrdb yet but its a pretty close copy of the strfry design, but meant to be an embeddable db like sqlite. Really impressed by the share nothing architecture, clustered indices and flatbuffers, so i copied most of that 😅. Keep up the good work! https://github.com/damus-io/nostrdb
Yes, I have seen nostrdb. I think it's a great idea, and that it will be a big benefit for native clients. Let me know if I can help in any way! I was thinking about it a bit and maybe flatbuffers is a bit overkill for the indexed nostr events in strfry, and I'm working on a branch that uses a custom event representation similar to nostrdb. I usually use flatbuffers by default because the generated code is convenient and it's easy to evolve the schema in a backwards compatible way. Also it comes with some nice utilities for debugging and securely parsing untrusted data (not needed here). BUT the core nostr event layout is pretty much fixed and saving some space here is important not least because it will let us pack more records into the page cache. I'll keep you posted on how that goes. Cheers!
{kind=link}