 Oddbean new post about login | logout
Oddbean new post about login | logout I'd like some design feedback on Alexandria. I'm working on an article editor feature. A screenshot of an early draft is below. The overall goal is to be able to type AsciiDoc-formatted text, preview it in rich text form as it would appear in the Alexandria reader view, then publish it as a cluster of kind 30040 and 30041 events. My thinking is to break the content down into sections. The content of each section will be published as a kind 30041 note. Each section will be indexed by a kind 30040 note, which will reference the content of the section as a kind 30041 and any subsections as 30040 notes. Question: How would you like to preview your published events? I see two options: 1. There are two preview steps: one is a "quick preview" you can see with a click while editing. It doesn't break the content down into 30040 and 30041 events, but it shows you what the nicely-formatted AsciiDoc content would look like. The second preview steps shows the content as it would appear in reader view, after it's been broken down into its constituent 30040 and 30041 events. This preview would have a confirmation dialogue that lets you approve or cancel publishing the events. 2. There's just one preview, and clicking the preview button while editing shows you the content as it would appear in reader view, broken down into 30040 and 30041 events. There would be no separate screen with a confirmation dialogue, and a publish button on the editor page would publish the events. I'd love to hear people's thoughts! #asknostr #alexandria #gitcitadel #nostrdev #nostrdesign https://image.nostr.build/2328fa70d7207dfbfa0196a869dadae7cb03925005786456a00e6107b905438e.png
Personally, #2, but I just know lazy / nontechnical people are going to feel railroaded into publishing and complain. They need confirmation screens, as many as possible lol. Recommend #1
Yeah it's more tedious for power users, but less error-prone for newbies. We can always add a power user mode later.
Does it necessarily have to be a 30040/41 combination? They will eventually be able to publish wiki pages, too right, or a 30040 that contains a wiki page or another 30040. So they need to be able to define which kind each section should have, with 30040/30041 simply the default. I'm just thinking that it might make sense to go full modularity in the design, from the start. Also probably need to put a help text above the editing field, that explains where you will define a split. Like, what happens with the content in the preamble? Does it go into a summary tag or does it get a preamble 30041? Is the header where you type in stuff that will end up in optional tags? Which tags will you process and how do they need to type them in? Can they see that information in processed form in the preview?
So, I'd go for #3: have a pre-selection dialog for the kind pattern (currently 30040/30041s or each kind alone), and have a small drop-down label, above or next to each section, where they can adjust the kind, but that is currently disabled and read-only. (They'll eventually need to be able to add/remove sections, as well, but that's future music.) 30041 alone because they may already have a 30040 and just want to add something new to the list. 30040 alone because they may just want to create an index for things that already exist.
LOL changed my mind, after Reading what @Low Information Voter said. Want three steps, like a little wizard, so that they can follow what the client is "doing". 1) Pretty asciidoc preview 2) Kind structure selection dialog 3) Split view with disabled kind labels
I would just do the publish button, tho. No fourth dialog.
I would think that creating an index of things that already exist would be a separate workflow. It might start while browsing in reading view. The user clicks a button next to a note that says "remix" or "add to index," and they are taken to an editor/search view where they can find other notes to add to the index and/or write their own content. I still need to think that through, since it's different from purely writing new content. Kind selection also impacts how we might parse the AsciiDoc content. If a user wants to publisj a wiki article, we probably wouldn't break down the content into smaller events. Rather, it would be one large wiki event kind. I'll have to think through how to represent that in the UI. Changing kinds may cause sections to merge together and such.
Would probably need a draft, for that workflow. A kind 30042 or something, for draft 30040s.
I have a doll To send you if that’s okay. If not, totally understand and respect 🫡 Hugs 🫂 my beautiful 🤩 fren
30041 by itself is perfectly reasonable - something to group together later on, perfectly alignes with the idea of 'Zettel'. You can publish 20 events of random notes coming from spontaneous ideas, the benefit being that it's nostr native but explicitely won't flood your followers' feeds like wiki articles.
In the writing of an article, i think we should focus on the 30040/41 pair. Keeps it simple, the idea being 30040/41 is about as basic an object you can create for 'knowledge'. Blogs, docs, etc. can always be broken down into grouped 30041. In the case for composing collages or grouping related ideas from different events, that's when we can think about what the process will be.
Okay, so hard-code everything to 30040/41 for the alpha release?
That would be easier to implement.
What about also allowing 30041 alone? I guess that already forces you to have a structure selection interface.
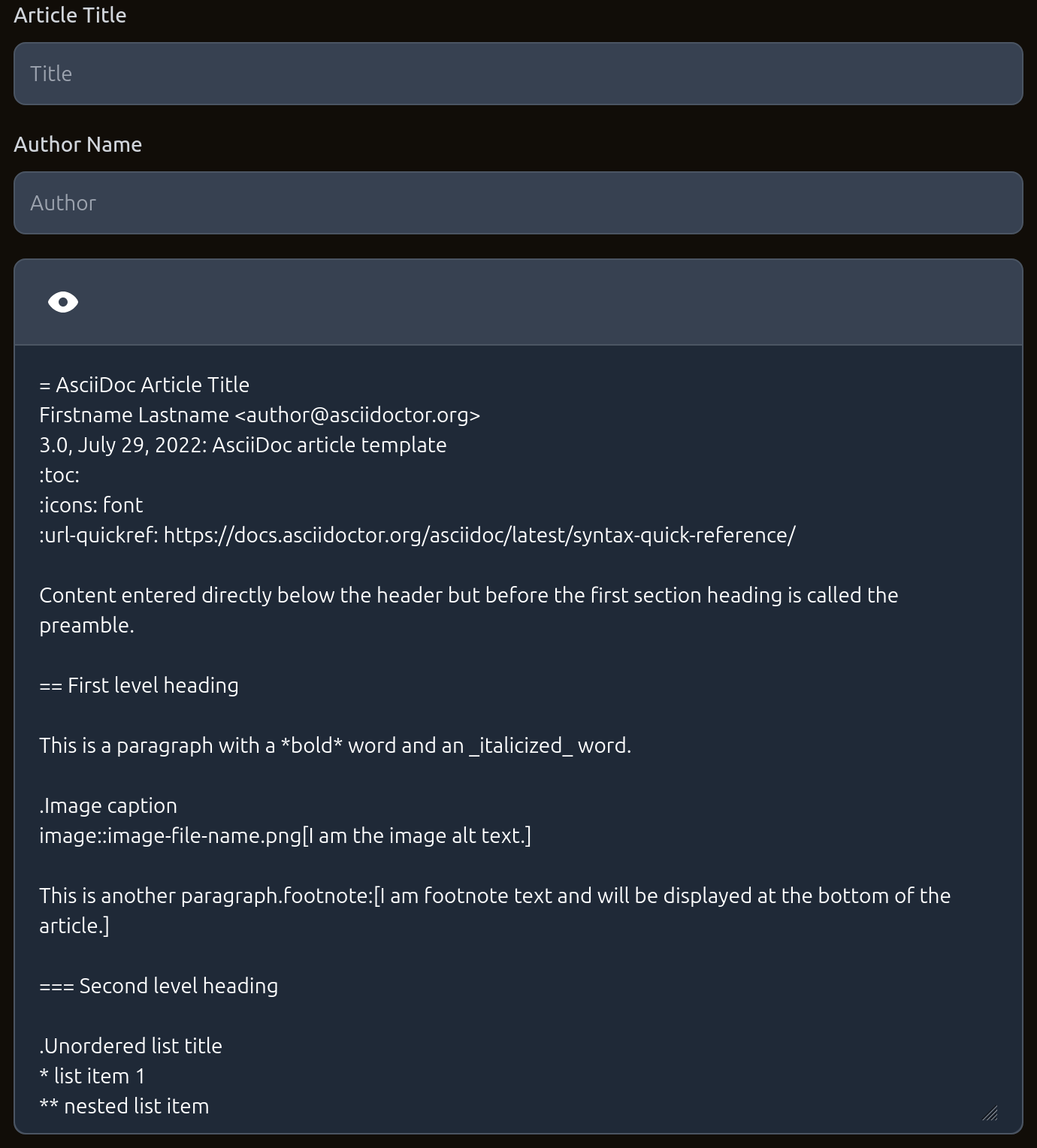
Title field is mandatory. Author is optional, even though it'll probably be added for books. Not really clear from the interface. Maybe add a red star next to "Title", or something, or demote author into the Asciidoc header.
The UX rule of thumb I've heard is "Don't punish the user before they've performed an action." So best practice is to make optional fields optionally visible, and not to show the red stars and such oj mandatory fields unless the user tries to submit the form without filling out all the necessary fields.
So, move author into ascii? Most 30040s won't be cohesive documents, like an original book, but rather someone's personal compilation of documents or snippets. A sort of remix. They won't have an author, but the 30041s might and they'd probably have author in the ascii or the form would get really messy. Right now, these are the mandatory tags (we need "d" and we need "title" to make "d"): [ "d", "<identifier>" ], [ "title", "<full_index_title>" ] And these are the optional ones: [ "author", "<author_name>" ], [ "i", "isbn:9780765382030" ], [ "t", "<topics about which the event might be of relevance>"], [ "published_on", "<date in the format YYYY-MM-DD>" ], [ "published_by", "<publisher of the source material>"], [ "image", "<URL pointing to an image to be shown with the title>" ], [ "summary", "<human readable description of the work>" ], [ "version", "<the volume, edition, or translation included>" ]
Pulling author from the AsciiDoc would be good. We could even have a prompt before sending to ask if the user wants to use whatever author name we found in the content.
Yeah, I saw the title and author lines in the asciidoc header and got confused because there's also a field. Maybe generally have a metadata section at the top of the preview, with the asciidoc header info pulled, for them to edit. And then we have it prepared for generating ePUB format. We just have to map to the require ePUB fields. https://docs.asciidoctor.org/epub3-converter/latest/
I didn't even think of the fact that Asciidoc can already have a bunch of the metadata we can process defined as header fields. 🤔 We should probably map-n-pull that into our json tags. https://docs.asciidoctor.org/asciidoc/latest/document/header-ref/
Have you already thought about something like a block based editor? Every block can be a certain kind. This could also facilitate remixing, you just pull other blocks in and out. For the preview I would expect it to always be the full document as it is later rendered on the client
{kind=link}
{kind=link}