 Oddbean new post about login | logout
Oddbean new post about login | logout local llama3.2 on your phone https://apps.apple.com/us/app/pocketpal-ai/id6502579498
Want to run bigger models and retain some privacy also check out https://venice.ai/what-is-venice nostr:nevent1qvzqqqqqqypzpq35r7yzkm4te5460u00jz4djcw0qa90zku7739qn7wj4ralhe4zqqsdjnp6rm8q9kdfctxrlc2zlhxa46qtjqeu9g25gqd4jj3fv92ucds4g2za4
Android: https://play.google.com/store/apps/details?id=com.pocketpalai
I'm curious how it is on battery life.. have you tried it out?
I just installed it now. I never used it before so I can't comment on battery.
No llama 3.2 1b though... my phone can't probably run 3b one
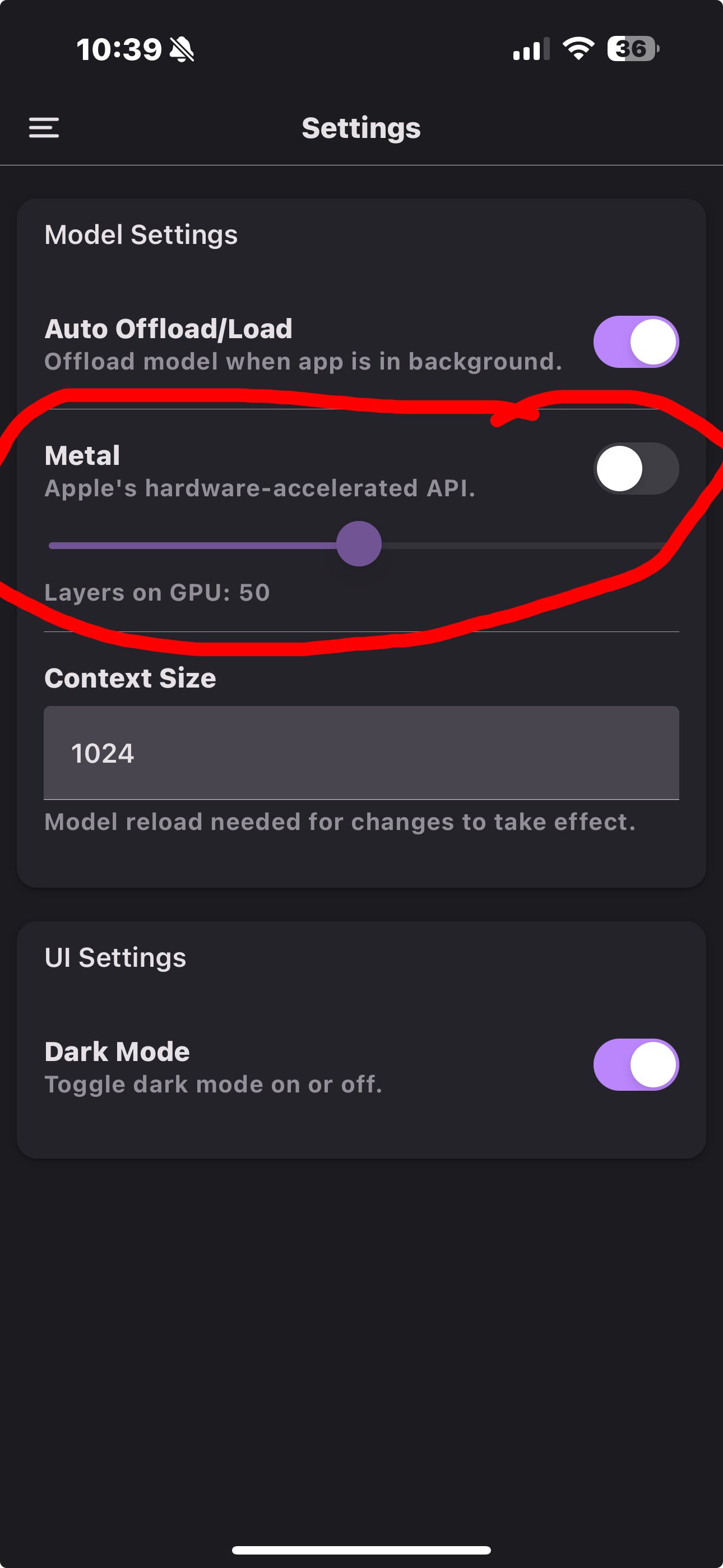
do you know what this is ? @jb55 https://i.nostr.build/5TgMpSBmYzV5okXr.jpg
Use gpu instead of cpu? I would think you would want that on 🤔
that’s what I was thinking.. what would you recommend for layers on GPU, default 50 or 100
Depends what your device can handle. Think of it like this: the full model might be 4Gb, if your device has 8Gb it might fit in memory, so 100% of the layers can be loaded there (and still have some room for the system and apps and such). But if your device has only 6Gb or 4Gb, the whole model will not fit, so you will need to test if 50% can be loaded into memory, or maybe less. At some point it might not make sense to use the GPU if only too little layers are loaded there, since the overhead of combining CPU + GPU work can predominate. Also, you need free memory space for the context window, so bigger contexts will consume more space and leave less space for layers, while smaller context leaves space for more layers.
Meh. Get a gaming GPU with 10GB+ VRAM run Ollama + Open WebUI, then set up a wiregaurd VPN to the machine connect to it on your phone and run much more powerful models.
I seem to recall that Ollama has some shady code that is probably harvesting your data.
when android?
Same app is available for android
{kind=link}