TLS’ only issues aren’t just CAs being a mess, it’s also an anachronistic protocol that just isn’t how you’d design something today. 1.3 is better, sure, but it carries tons of legacy garbage and most clients still have fallbacks and logic for it.
I also dislike QUIC for being a lazy, poor version of TCP. Middleboxes suck sometimes but sometimes do useful things (eg on a plane TCP is terminated before it goes to the sat, improving latency and throughput compared to UDP things with retransmissions, middleboxes can use MSS clamping to avoid fragmentation, etc). QUIC largely failed to consider these things and just said “screw all middleboxes” (compare to eg tcpinc which got similar encryption properties without being lazy). QUIC exists to rebuild TCP in user-space cause kernels sometimes suck, but for those of us with an operating system newer than five years old that’s not a problem we have. Worse, sometimes your OS has specific useful features (eg MP-TCP) that you don’t want twenty apps to have to rewrite. FFS this is literally the point of having an OS! The only promise QUIC made that isn’t as trivial in TCP is FEC, but they gave up on it cause…I dunno why.
Note that QUIC is useful on the web for helping to and the multi-connection/head-of-line blocking problem. But if you aren’t fetching a bunch of resources from the same server across different streams where you can use each resource individually on its own this doesn’t apply (and it requires integration work to make it apply).
Errr avoid the multi-connection (and associated initial small window sizes)/head-of-line-blocking tradeoff.
We are indeed fetching a bunch of resources from the same server across different streams.
Libp2p allows us to use multiplexing so we can open as many bi-directional streams as we want over a single connection, it's awesome. We use it for Airlock (permission system for the decentralized GitHub).
I understand your point about the OS handling TCP instead of each app handling networking individually, which does make a lot of sense. I wish there were a plug-and-play TCP+TPO+Noise library that could handle multiplexing! Would be a nice addition to include in libp2p.
TFO*
I mean if you drop the TFO requirement it’s easy - just open many connections. But just fetching many resources isn’t sufficient to want QUIC - you have to be doing so immediately after opening the connection(s), the resources have to be non-trivial in size (think 10s of packets, so the text of a note generally doesn’t qualify) and have a need for not blocking one on another, which is generally not the case on a mobile app - server can send the first three things you need to paint the full window first and then more later.
It’s a desktop app for decentralized GitHub on Nostr. The amount of data is non-trivial in size (sometimes). Repos can be large. This is why we’re using merkle tree chunking for large files as well. I want the reduced RTT.
It’s just a head-of-line-blocking question, though…I imagine mostly you’re not downloading lots of CSS/JS/images, which is the big head-of-line issue HTTP clients have - they can render the page partially in response to each new item they get off the wire.
I assume you don’t, really, though? You presumably get events back from the server in time-order and populate the page down in time-order, so mostly one event stalling the next won’t make all that much difference in UX?
 Oddbean new post about login | logout
Oddbean new post about login | logout 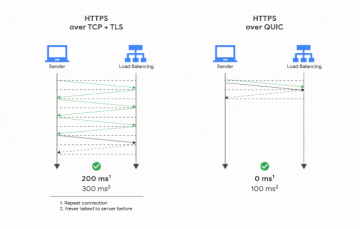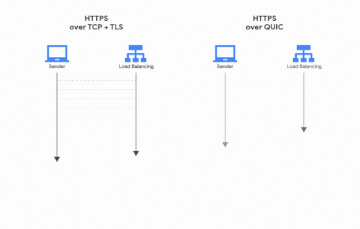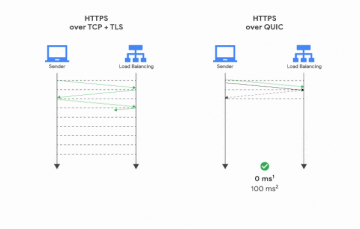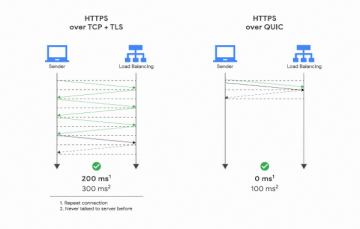{kind=link}