 Oddbean new post about login | logout
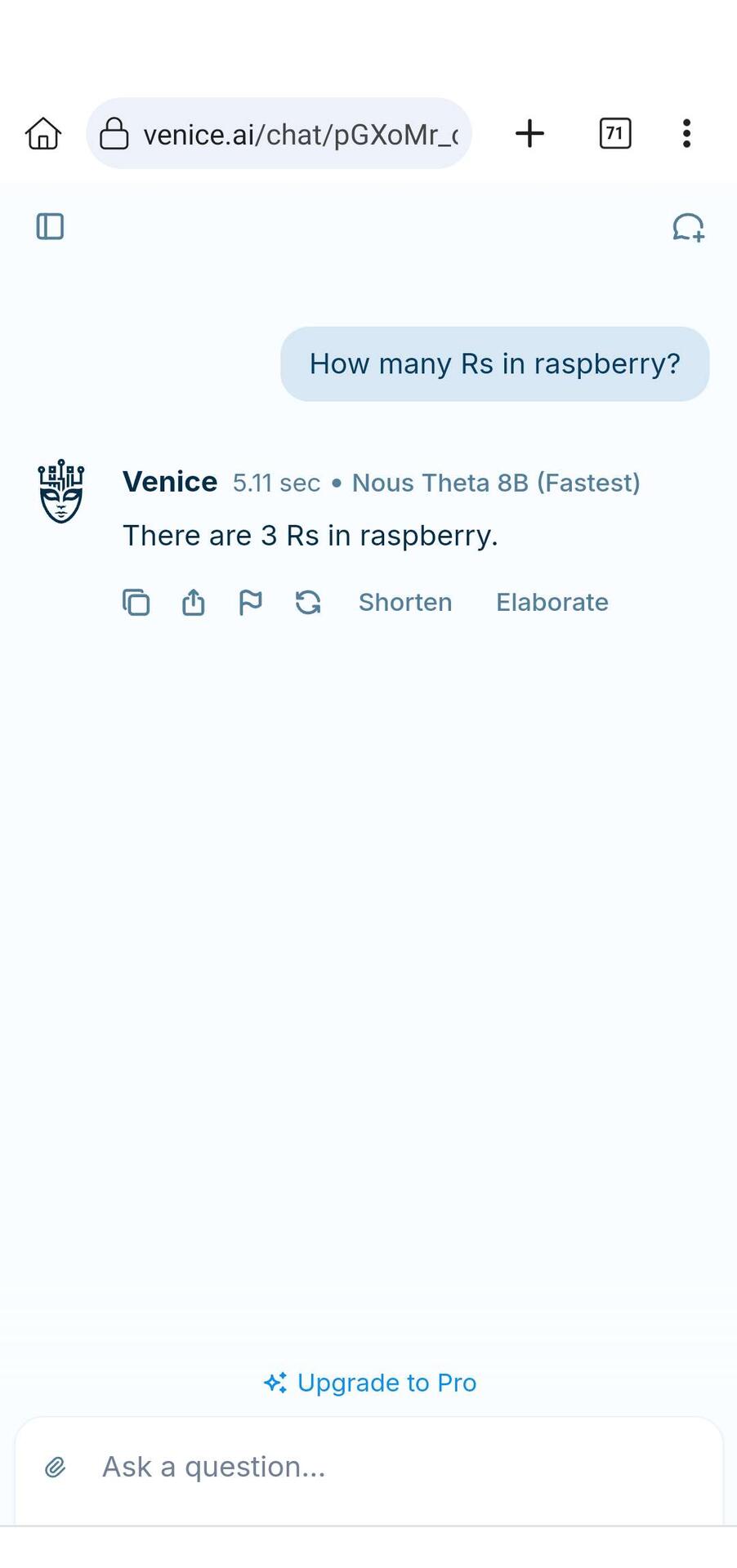
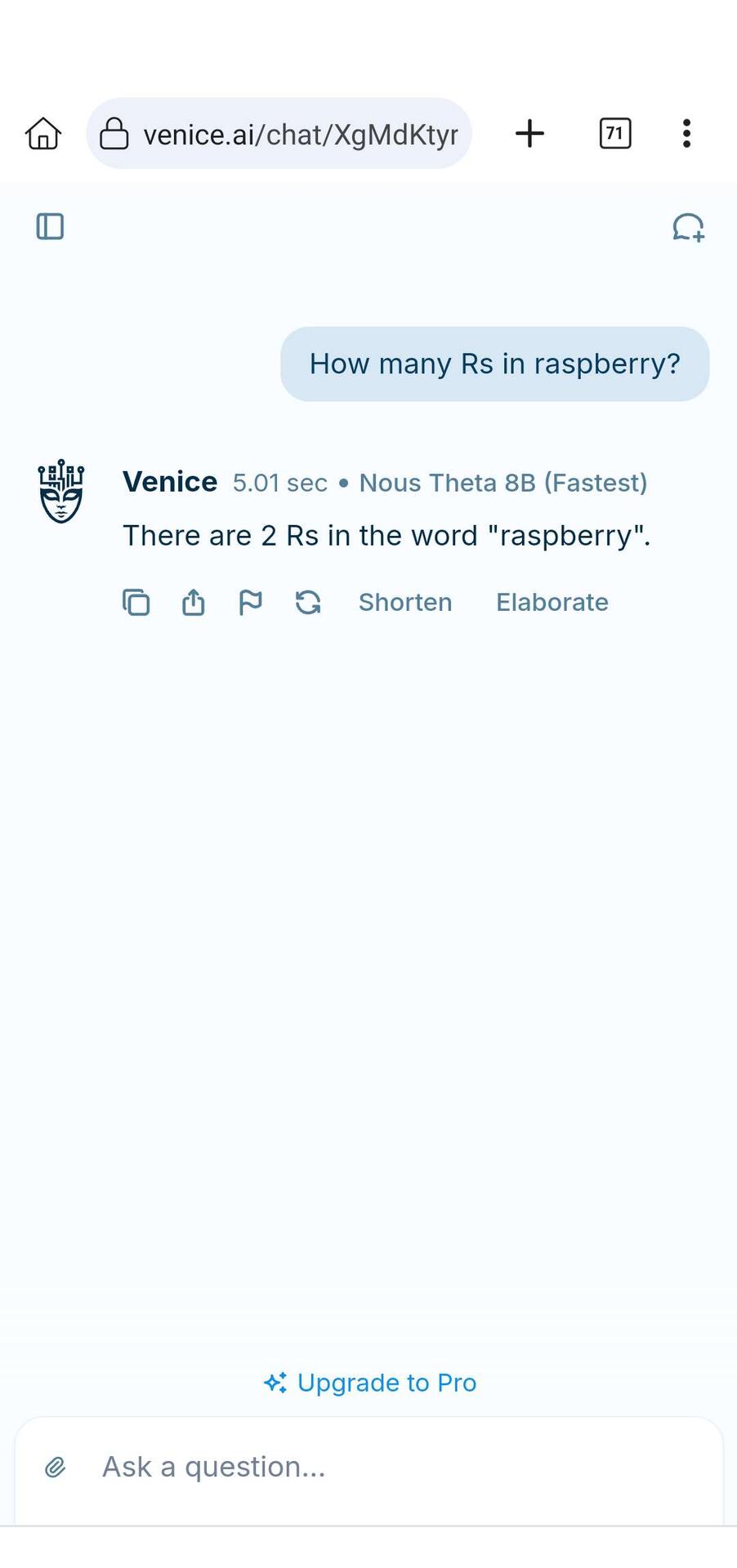
Oddbean new post about login | logout Venice.ai got it right. https://image.nostr.build/be3ddb1232e61a2fcbb58d70a2a595b7db7c7fb55605527f7ac8b9b158c03b30.jpg I asked it a second time and it got it wrong 🙃 https://image.nostr.build/78ab607f904c51f4a54e76c9af544903b702d9b70b769f9a4e8dcd059faa6c67.jpg
The strawberry test is quite iconic. Many models are secretly "hard-coded" to avoid failing it so they don't appear flawed, but it highlights some fundamental weaknesses in LLM architecture and core limitations. Playing chess also reveals these flaws.
{kind=link}
{kind=link}