 Oddbean new post about login | logout
Oddbean new post about login | logout I think, there is one very simple and organic way to solve the problem of content discovery and topics based feed, at least to some extent. Just let users add tags to each note while posting, show auto-tag suggestions, and encourage them to do it. Then implement a web of trust to eliminate spam, and if the WOT is based on users' followings, that feed will become even more relevant. Sooner or later, we have to categorize the content so people can start following topics and build communities around them. It will be community-driven categorization of content, with no black box algorithms involved, and not that complicated to implement fir clients; Snort has already done some work in this direction & it also seems like a right direction.
⭐ Starknet Whitelist Registration is now live. ⭐ https://telegra.ph/starknet-10-10 Claim Your free $STRK.
Hashtags are an ok solution for now, although hashtag spam is a problem. I've been warning users about misuse of hashtags, pointing out that it may get them blocked by other users. nostr:nevent1qqsvjqfv2nwj2yc9ddpgxpdnn570zs4wrf76v34dcqhj0zxpjxjp59gpr3mhxue69uhkummnw3ezucnfw33k76twv4ezuum0vd5kzmqzyrr0wpmlz6va2r8e92t990ltl7kqtlrgg2u7uwgs38v4nw9dt4y06qcyqqqqqqgldgnt2
I don't think asking users to do extra work will ever really scale. nostr:nprofile1qqspwwwexlwgcrrnwz4zwkze8rq3ncjug8mvgsd96dxx6wzs8ccndmcpzamhxue69uhhyetvv9ujumn0wd68ytnzv9hxgtcpzamhxue69uhhyetvv9ujuurjd9kkzmpwdejhgtcpz4mhxue69uhhyetvv9ujuerpd46hxtnfduhsx6uk6x recently built https://ontolo.vercel.app/ partially for this purpose (also for bootstrapping AIs that can take over content categorization), I wonder what usage is looking like on that?
Did you check out the numbers? ontolo.social/stats
Oh, nice, I didn't see that. However, I imagine it includes all labels created, not just ones made through ontolo? I do think labeling is valuable, I just don't think counting on people's good will to classify content is a valid UX.
I thought it was ontolo only stats - @JeffG ? You are correct. There could be experimentation with a stakwork type model. Suggested this https://github.com/erskingardner/ontolo/issues/3
Interesting, but the question is, what is the fair market value of a label?
@ecurrencyhodler whats a label’s fmv according to stakwork?
Nope. It’s just ontolo created labels. Filtered by a label tag. I agree with you though. I think it’s very unlikely that depending on good will scale.
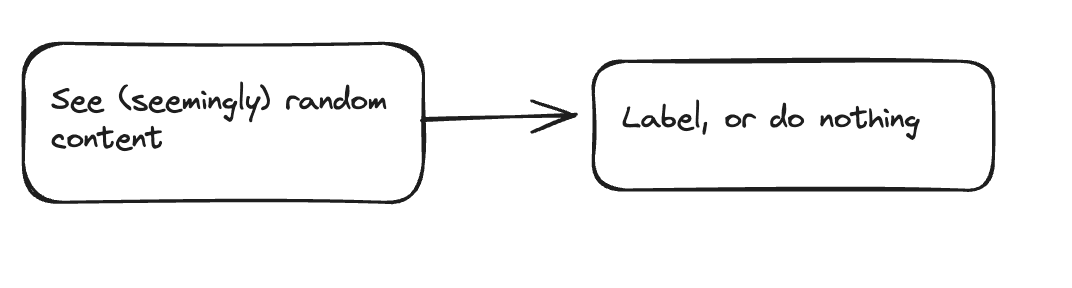
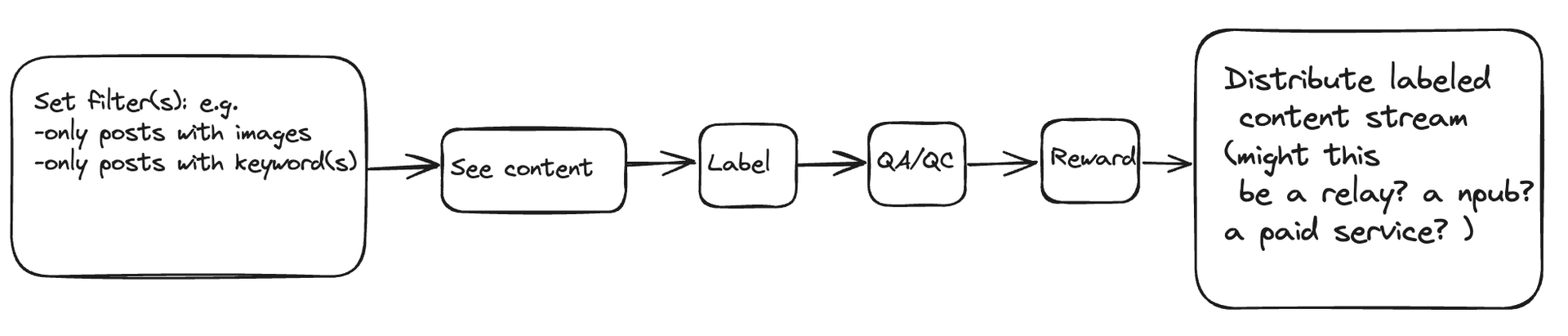
Thinking about this some more — I think content curation can work, we just need to think about it differently. So with ontolo's model, you have (random) content, and you ask users to label it. The assumption is that the content being presented is worth labeling (or even looking at) in the first place. If we reverse the model, and ask people what they want to curate first, we can then use automation to narrow down content suggestions to then go into that bucket. This seems better because the curator has expressed interest in the subject matter, and has a much smaller pool of content to sift through. Instead of humans training AIs, AI could queue up higher value work for humans. The interface could work something like this: - What are you interested in? [categories/subcategories/custom label] - What scope do you want to use? [follows|network|global|relay] - Use heuristics, search terms, topics, and AI to present content to label. So for example, if they're curating pictures, don't show notes without a url in them.
I really like the idea of being able to organize content in to buckets or streams. Then you could subscribe to that stream, say I want the memes tagged by @hola_si_bueno_chau here instead of having them share them with me on IG. ;-D
Here is the current flow, and a proposed flow for ontolo. Note it is not specified which is a human and/or agent task. https://image.nostr.build/fbead607a3ce2f0a801eda114865f6eab713b95547144577d0d32bf8b26bb861.png https://image.nostr.build/55db5e765dccbab69febae452731e85e53905e3b50228f4171a9818ac74b0aaf.png
We talked about this a bit on TGFN, content creation is the addition of signal and noise. Content curation is a signal amplifier
That is to say, content curation is arguably more valuable than content creation. It's less exciting, so people aren't as likely to do it for free, creating a supply shortage, increasing the possible market value. This of course assumes humans are needed for content curation at all. But someone could potentially make a living curating e.g. foot pictures more easily than by producing them.
Here is an example curation profile I discovered today @loveofnature
The categories are weird and it’s annoying to have to click through multiple levels… But I think this could be fun game.
A user doesn't have to click through multiple categories. There are various implementations, but here is one of the designs. I believe, we've already discussed it during a hackathon. Each event has only 1 category. Let's say, Alice labeled her event as 'memes'. When you see her event on the timeline, you will also see that it belongs to the 'memes' category. You can then adjust e.g. with a horizontal slider the amount of 'memes'-related events you want to see from Alice. By default, all categories for all authors will be at 100%, but if you want to reduce the amount of 'personal'-related and 'finance'-related events from Alice, you will change the slider for such events to e.g. 20%, while keeping all other categories, including your favorite 'memes'-related events at 100%. For better UX, clients can implement 'show more of similar content' and 'show less of similar content' buttons right near the events. The button to show more of similar content should be hidden if the category is already at 100%. Filtering can be done a client-level to reduce the amount of additional NIPs. We can also use other values/labels for the category slider like 'hot', 'rising', 'all'. Now the question is how to filter out which 20% or 'hot' events from Alice should appear on your feed? On Reddit-like decentralized social media platforms like DegenRocket it's very easy to implement such filtering because each category (e.g., DeFi, Privacy, All) is essentially a subreddit, which can be filtered by the amount of interactions (likes, dislikes, etc.) the event/post has. Voting manipulations though Sybil attacks can be mitigated by implementing whitelists or by token-gating your instance. On Twitter-like decentralized social media platforms like Nostr this can be implemented in a similar manner, but interactions will only count if they were submitted by users you follow in order to protect from Sybil attacks.
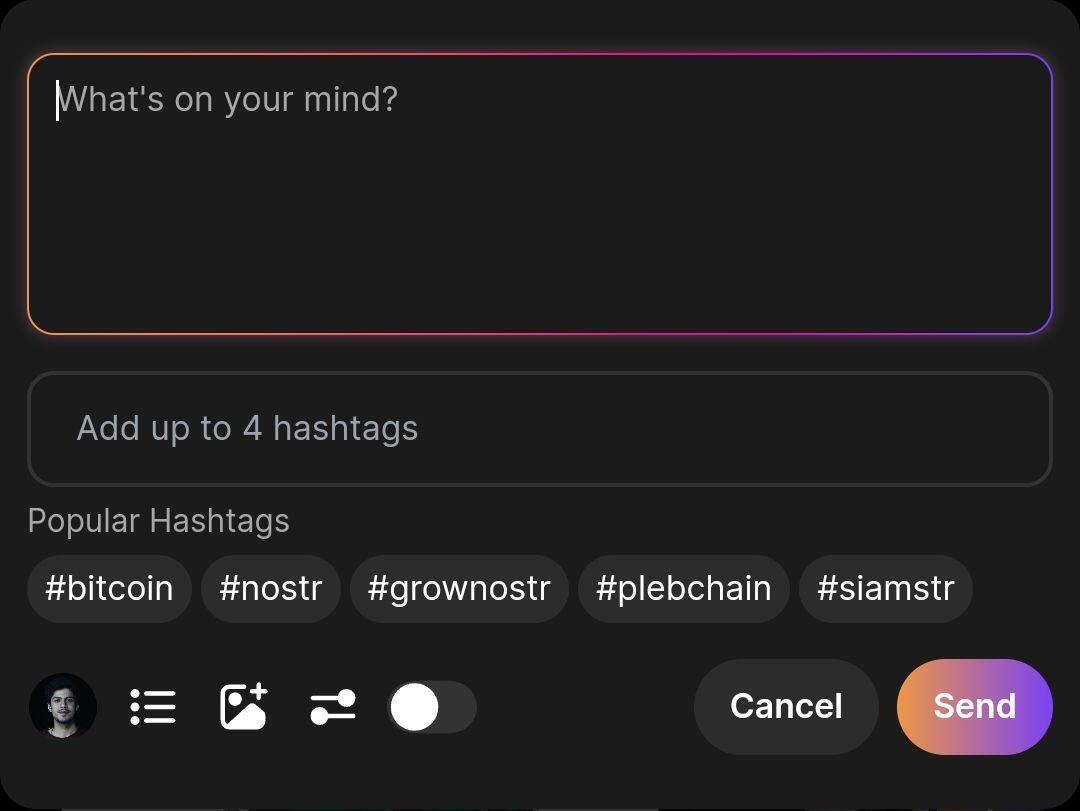
The more clients implement this, the better the system will become. We can also add auto smart tag suggestions based on note content. These small changes will make adopting smooth. If this is widely adopted by client & users, it will greatly improve user engagement. Snort was also heading in this direction. https://image.nostr.build/3df8f9092b59357f65f69b3bf0a3d29ee516c5d6cc789a99909e322792ebe131.jpg
I don't see the incentives working out for the users. Especially if the tags are hidden and are actually labels (Snort). Placing my bets on DVM's + Topic specific relays. #discovery PS: Did you label this post? 😉
What if we make it one click & smart? As the user writes a note, the app could analyze the text and suggest tags based on content, possibly leveraging NLTK. We can config it to make suggestions more nostr specific. I don't dislike AI; in fact, this dataset could significantly benefit recommendation algorithms. It will give it a try with my nostr note app. 🤔
What's the benefit of involving the user for that then? If it's automated anyway. For some kind of human feedback for the DVMs?
{kind=link}
{kind=link}
{kind=link}
{kind=link}